2023.11.28 组会内容
预备知识:
Deep Cross-Modal Projection Learning for Image-Text Matching大工卢老师 ECCV14
跨模态投影匹配 (CMPM)
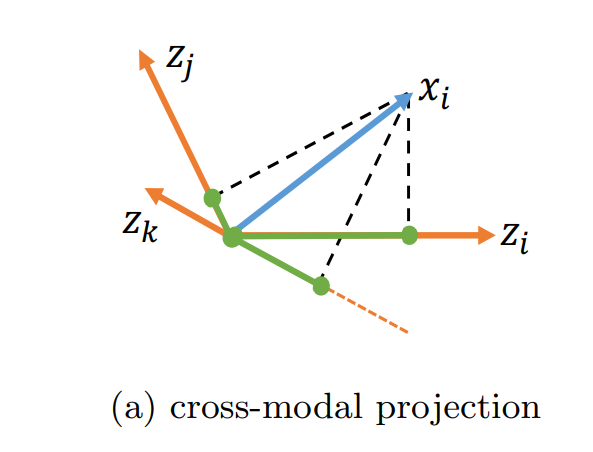
$${ (x_i, z_j), y_{i,j} }_{j=1}^n$$
$$y=1 | y=0$$
$$p_{i,j} = \frac{exp(x^T_i \bar{z_j)}}{\sum_{k=1}^{n} exp(x^T_i \bar{z_k})} s.t.\bar{z_j}=\frac{z_j}{||z_j ||} $$
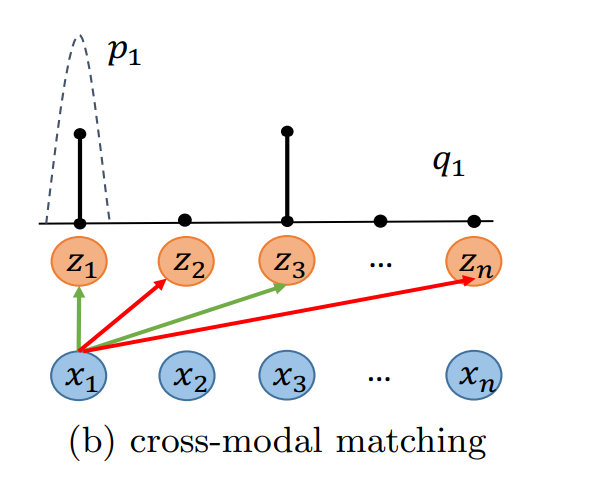
$$q_{i,j} = \frac{y_{i, j}}{\sum_{k=1}^{n}y_{i,k} }$$
$$L_i = \sum_{j=1}^{n}p_{i,j} log\frac{p_{i,j}}{q_{i,k} + \epsilon } =KL(p_i|q_i)$$
$$L_{i2t}=\frac{1}{n} \sum_{j=1}^{n}L_i $$
$$L_{cmpm}=L_{i2t} + L_{t2i}$$
对于给定的一幅图像,在计算匹配损失时考虑了小批文本中所有的正、负候选文本,从而避免了传统的双向rankingloss的专用抽样过程。
跨模态投影分类损失(CMPC)
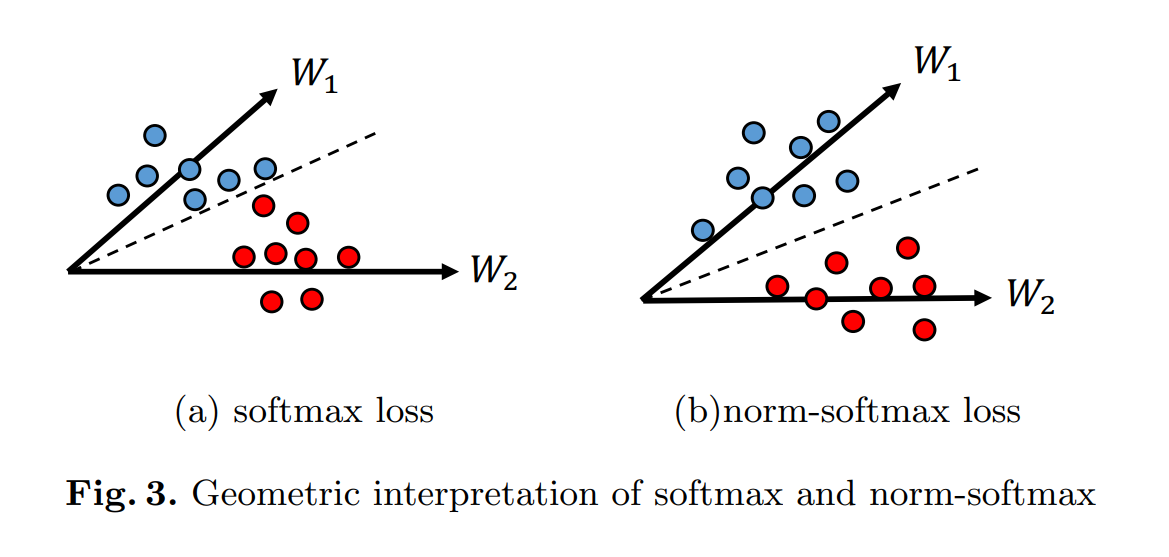
norm-softmax loss的直观解释如上图所示。可以看到,对于原始softmax,分类结果取决于$|W_{k}||{x}| \cos (\theta_{k}),(k=1,2)$,其中$θ_k$表示角度在$x$和 $W_k$ 之间。对于norm-softmax,所有的权重向量都被归一化为相同的长度,分类结果只能依赖于$|{x}| \cos (\theta_{k})$。这种限制鼓励特征 x 沿着权重向量更紧凑地分布,以便正确分类。
$$L_{ipt}=\frac{1}{N} \sum_{i}^{} -log(\frac{exp(W^T_{y_i}\hat{x_i})}{\sum_{j}^{}exp(W^T_{j} \hat{ {x_i}})})
\space \space \space s.t. \left || W_j \right ||=r,\hat{x_i}=x^T_{i}\bar{z_i} \cdot \bar{z_i} $$
$$L_{t2i}=\frac{1}{N} \sum_{i}^{} -log(\frac{exp(W^T_{y_i}\hat{z_i})}{\sum_{j}^{}exp(W^T_{j} \hat{ {z_i}})})
\space\space\space s.t. \left || W_j \right ||=r,\hat{z_i}=z^T_{i}\bar{x_i} \cdot \bar{x_i}$$
$$L_{cmpc} = L_{i2t} + L_{t2i}$$
跨模态投影将图像-文本的相似性整合到分类中,从而加强了匹配对之间的关联
ID Loss
将样本分为几个类,常用为softmax函数
$$L_{id} = -\frac{1}{n} \sum_{i=1}^{n}log(p(y_i|x_i)) $$
多模态对齐
Cross-Modal Implicit Relation Reasoning and Aligning for Text-to-Image Person Retrieval CVPR23
主要目的
实现多模态数据的底层对齐能力,首先设计了一个隐式关系推理模块在掩蔽语言建模(MLM)范式。为了全局对齐视觉和文本嵌入,提出了相似性分布匹配,以最小化图像-文本相似性分布和归一化标签匹配分布之间的KL分歧。
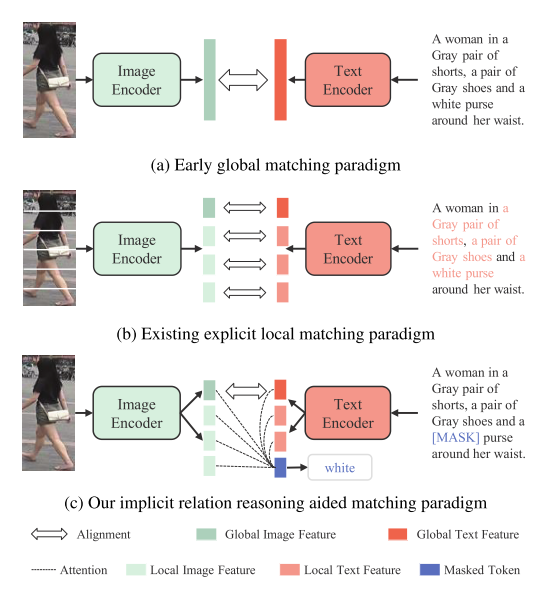
问题与解决
1.受限于变化的投影长度,CMPM因此不能精确地控制投影概率分布,使得在模型更新期间难以关注硬阴性样本。为了探索更有效的跨模态匹配目标,提出了一种图像-文本相似性分布匹配(SDM)损失
2.以前的一些方法要么冻结了部分参数,要么只引入了CLIP的图像编码器,这导致它们无法充分利用CLIP在图像-文本匹配中的强大功能,这里直接进行使用
方法
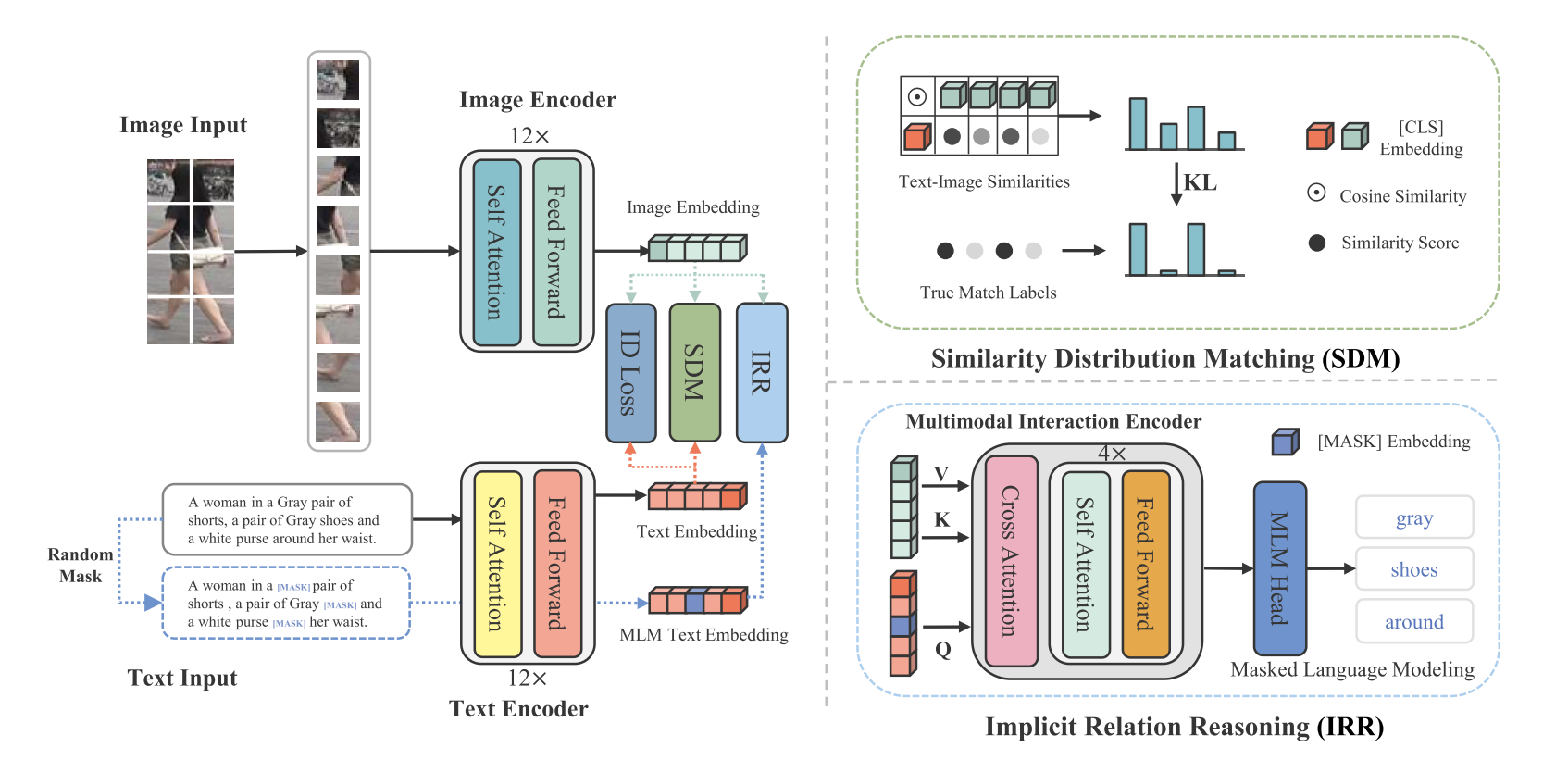
这里随机15%打上掩码,然后用ImageFeature 预测
Similarity Distribution Matching (SDM)
$$p_{i,j} = \frac{exp(sim(f^v_i, f_j^t)/\tau )}{\sum_{k=1}^{n} exp(sim(f^v_i, f_k^t)/\tau)}$$
$$L = KL(p_i\left|\right|q_i)=\frac{1}{N}\sum_{i=1}^{N}\sum_{j=1}^{N}p_{i,j}log(\frac{p_{i,j}}{q_{i,j} + \epsilon }) \space\space s.t.q_{i,j} = \frac{y_{i, j}}{\sum_{k=1}^{n}y_{i,k} }$$
这里和CMPM一样吗!好像不一样,这里把投影改成了相似度
$$L = L_{irr} + L_{sdm} + L_{id}$$
ViLEM: Visual-Language Error Modeling for Image-Text Retrieval ICCV23
主要目的
粗粒度的全局对齐忽略了图像和文本之间的详细语义关联。提出了一个新的代理任务,命名为视觉语言错误建模(ViLEM),注入详细的图像-文本关联到“双编码器”模型,通过“校对”文本中的每个单词对相应的图像,提出了一个多粒度的交互框架来执行ViLEM通过交互文本功能与全局和局部的图像功能。

问题与解决
1.对比目标只针对图像和文本的全局特征,导致对图像和文本的局部语义的开发不足。因为用全局信息进行对比
2.其中一部分单词被随机掩蔽,并且模型被训练以恢复具有全局视觉特征的掩蔽单词。这些工作忽略了局部文本语义和局部视觉信息之间的关联,阻碍了细粒度的图像-文本对齐的学习。这里是提出了2.1中掩码学习的缺点。这篇文章是生成看似合理,但是和视觉不对应的错误信息。关于同义词的问题,实验时影响不大。
方法
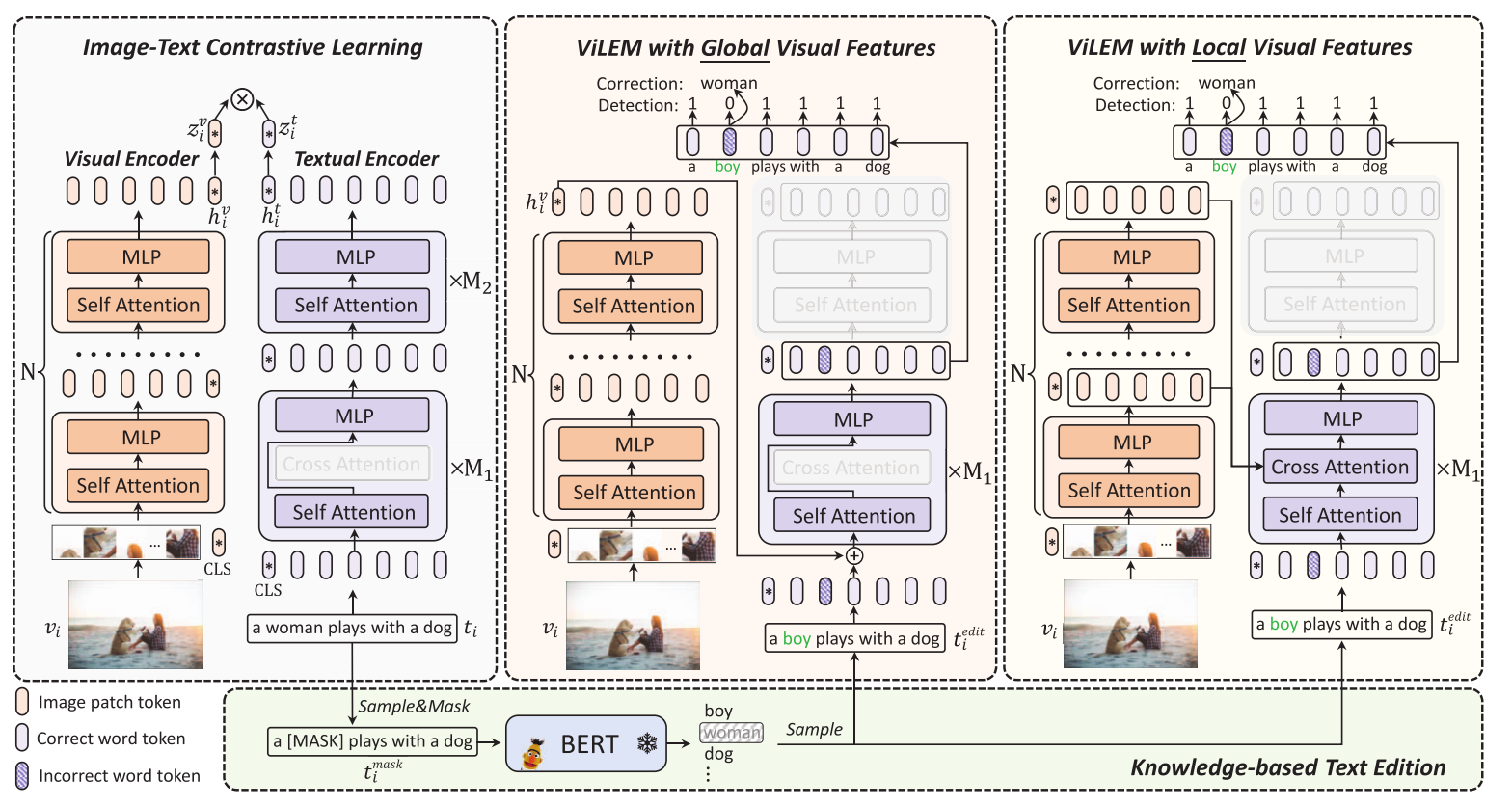
$$L = L_{align}+ \alpha_1 L_{EML} + \alpha_2 L_{EMG}$$
CLIP-Driven Fine-grained Text-Image Person Reidentification
主要目的
模态之间的巨大差距,现有的方法将原始模态特征嵌入到同一个潜在空间中进行跨模态对齐,挖掘模态内的判别线索和模态间的对应关系。多粒度的全局特征学习(MGF)模块,跨粒度特征细化(CFR)和细粒度对应发现(FCD)模块。
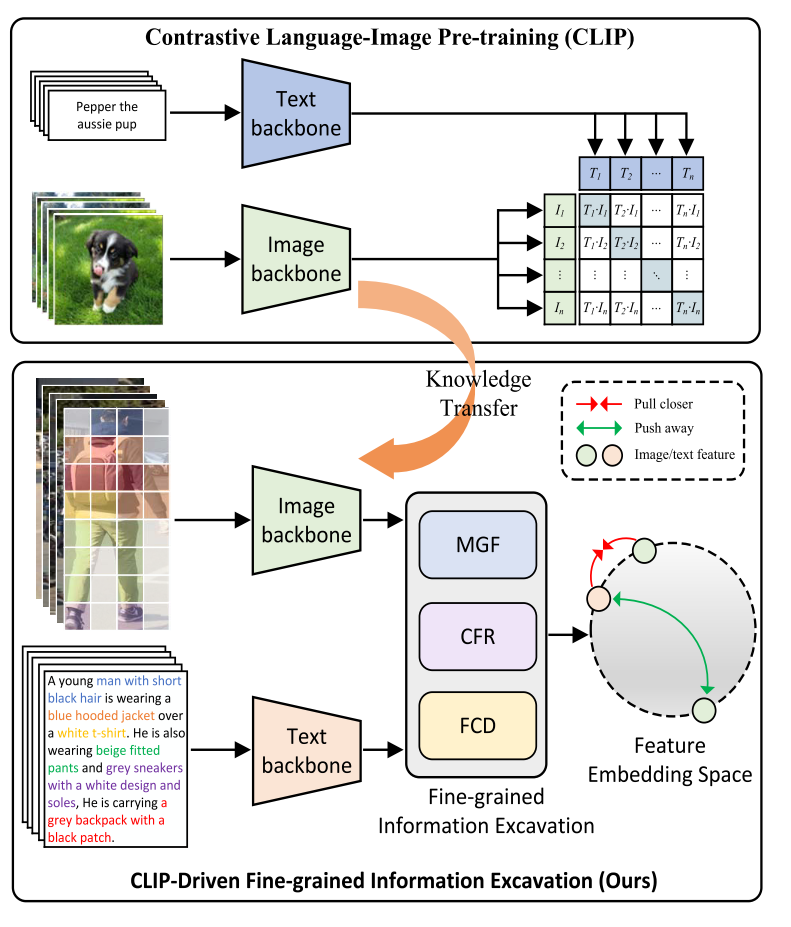
问题与解决
有的方法通过单模态预训练的模型参数初始化网络,忽略了多模态对应信息。此外,从上述初始化的网络中提取的图像和文本嵌入过度挖掘单个模态内的信息,这增加了跨模态对齐和网络优化的难度。
方法

CLip模型在Bert模型的最后,使用投射层将764维的向量投射为512,22年的论文有研究这会导致精度下降。
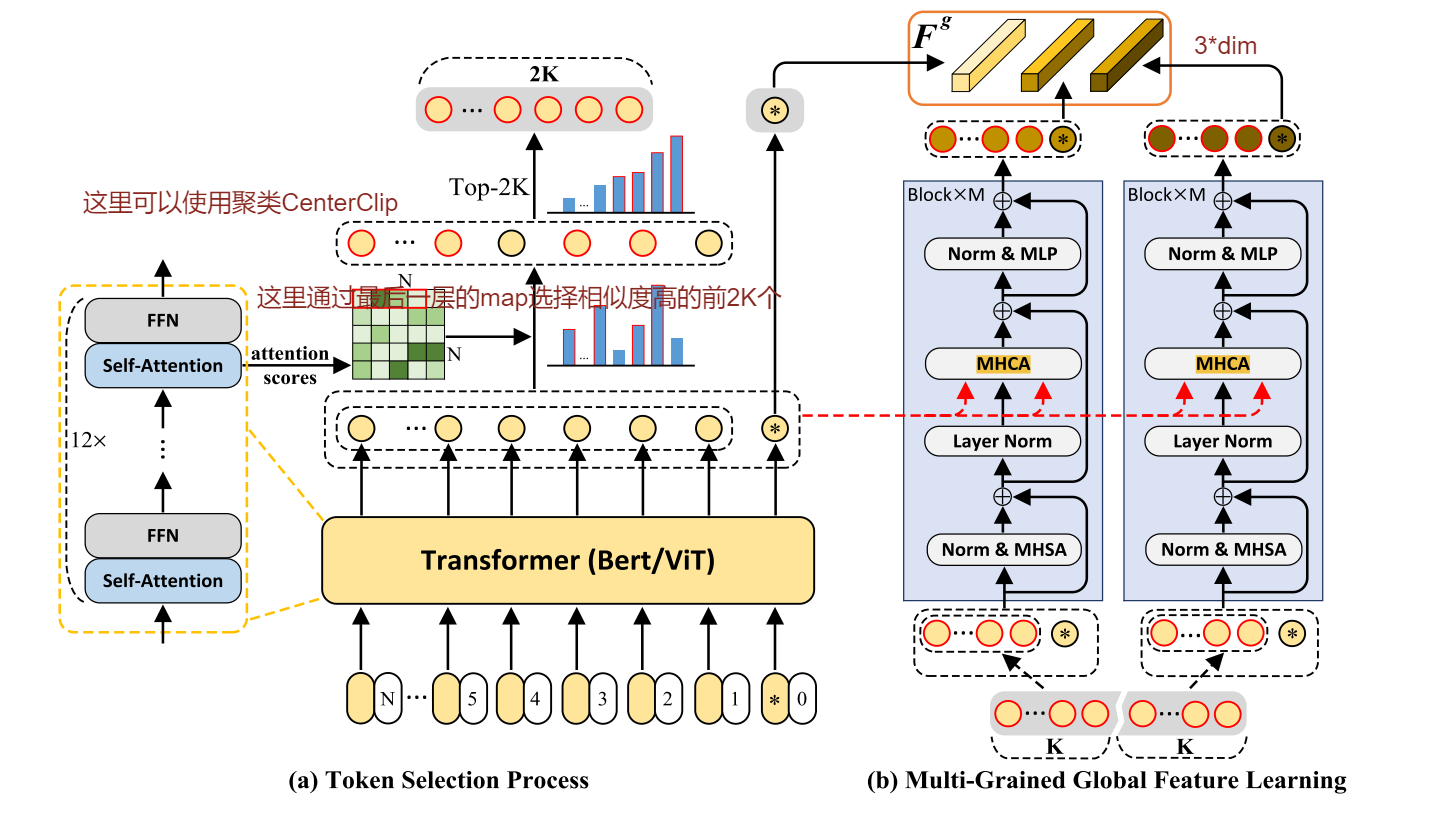
全局特征由所有局部特征支配,这种同时考虑所有局部特征的方式减少了一些重要局部特征的影响。
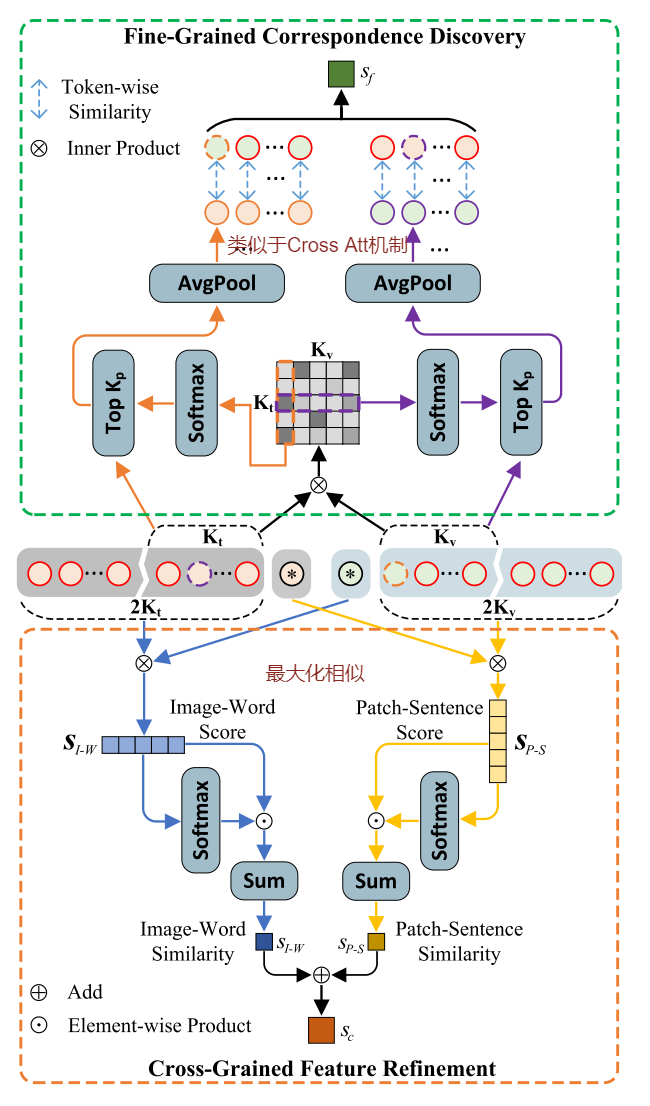
Diversity Regularization:多样性正则化,没听过。对不同粒度的特征施加多样性约束$L_{div}$以避免信息冗余
$$L_d = \sum\nolimits_{i\in [l,m,h]}\sum{j\in[l,m,h],i!=j}(\frac{v_i\cdot v_j}{||v_i||_2||v_j||_2 }+\frac{t_i\cdot t_j}{|t_i|_2|t_j|_2}) $$
$$L=L_{cm} + \alpha_c L_{c} + \alpha_d L_d$$
训练结构
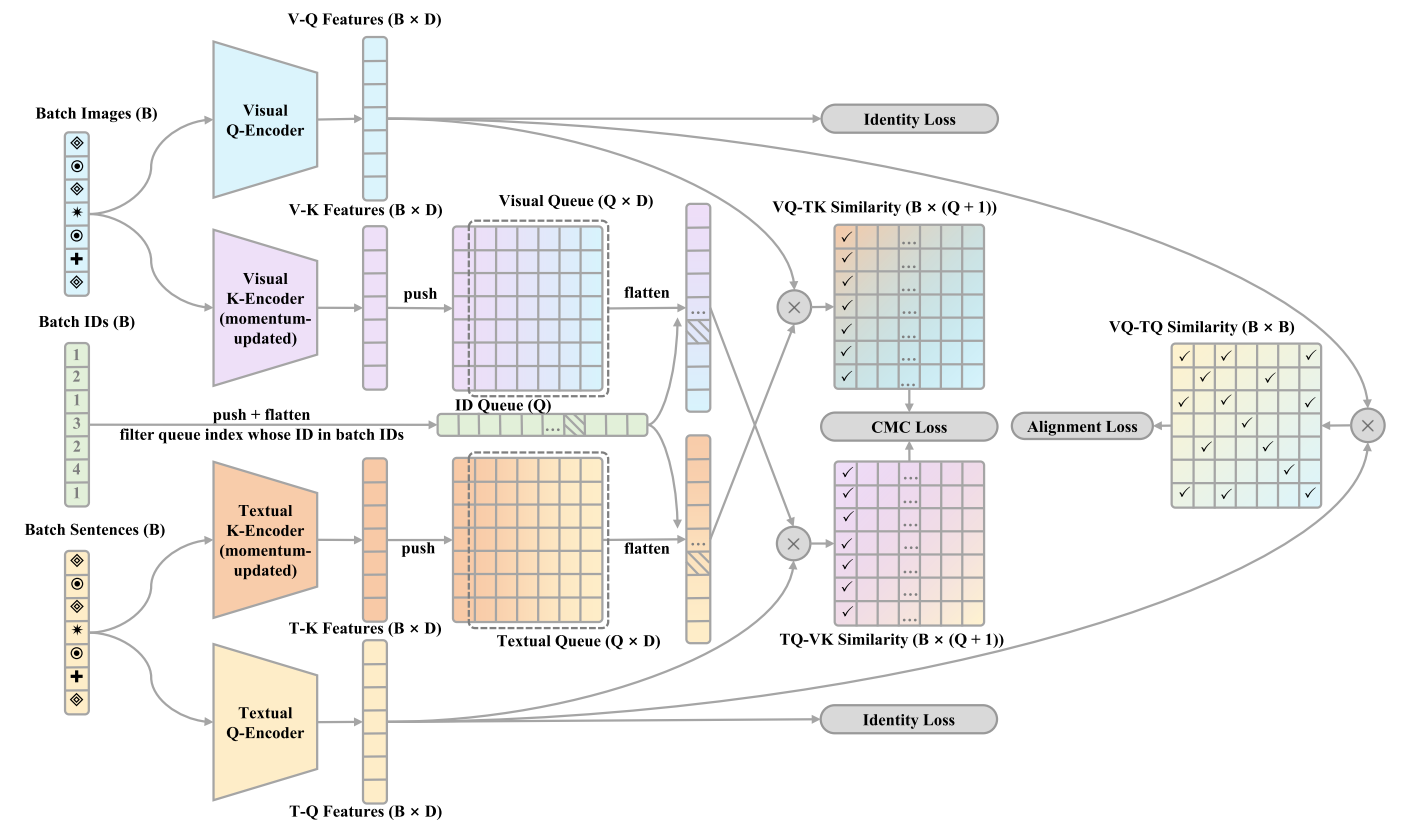
Text-Based Person Search with Limite
利用MoCo的方法进行训练
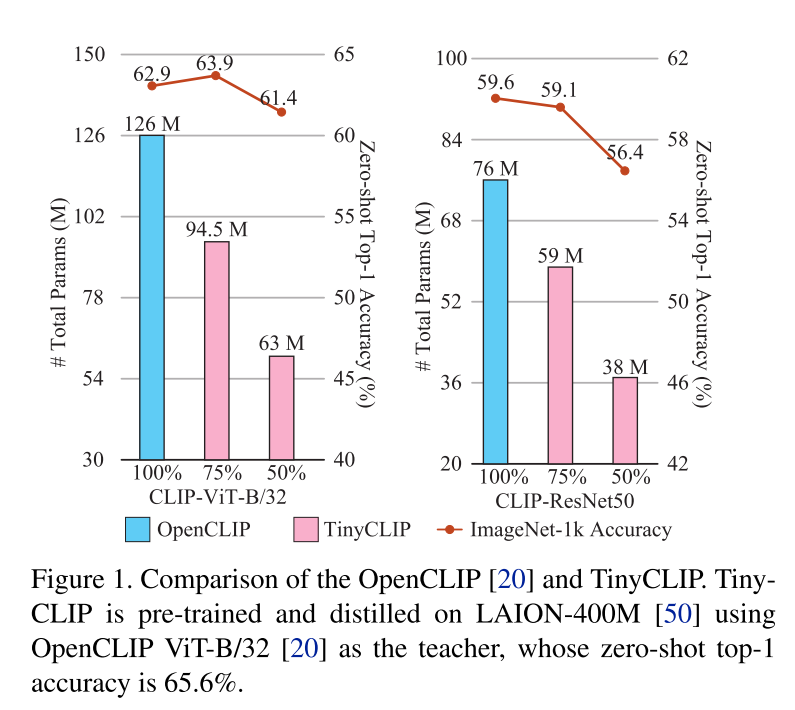
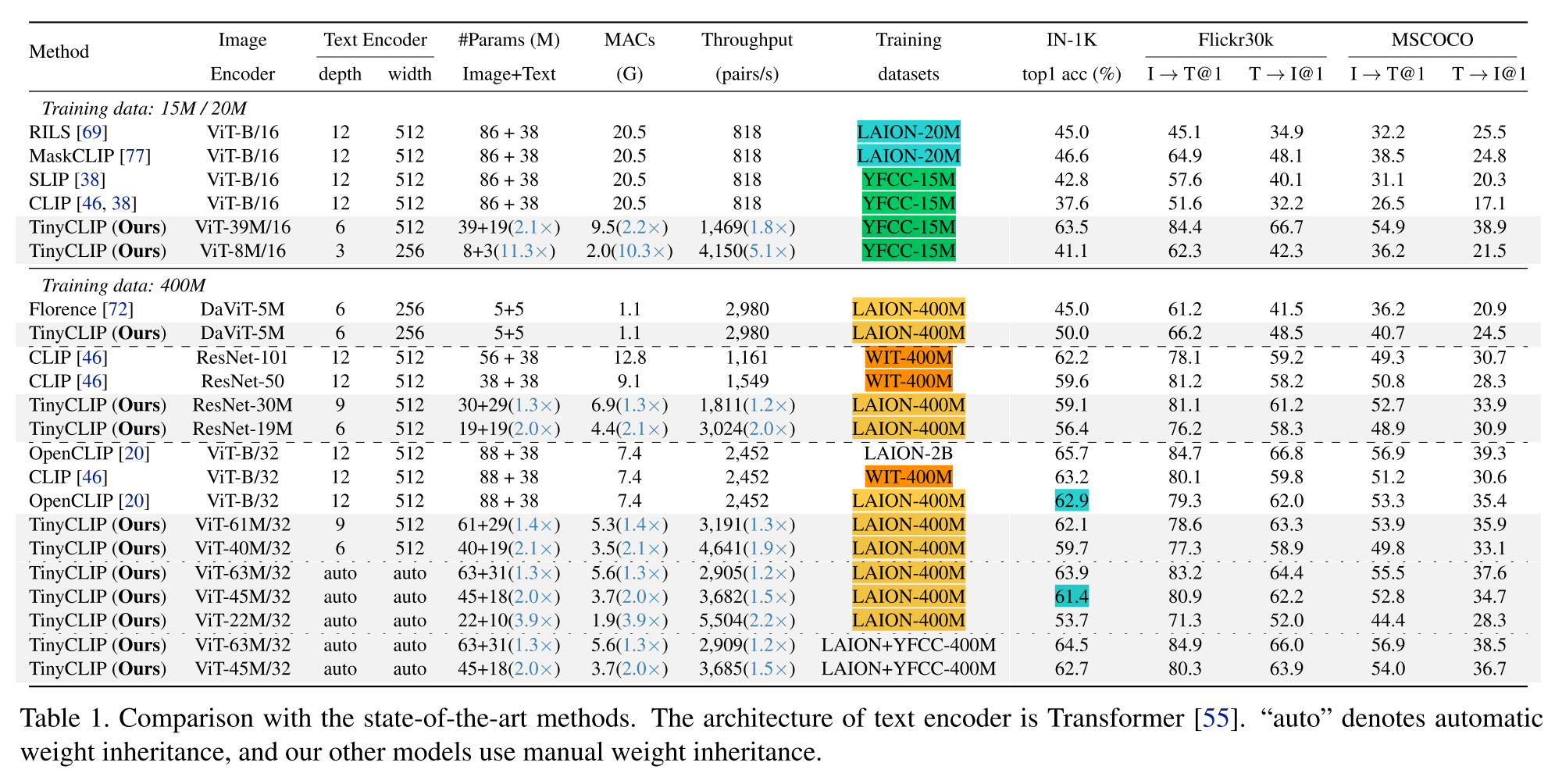
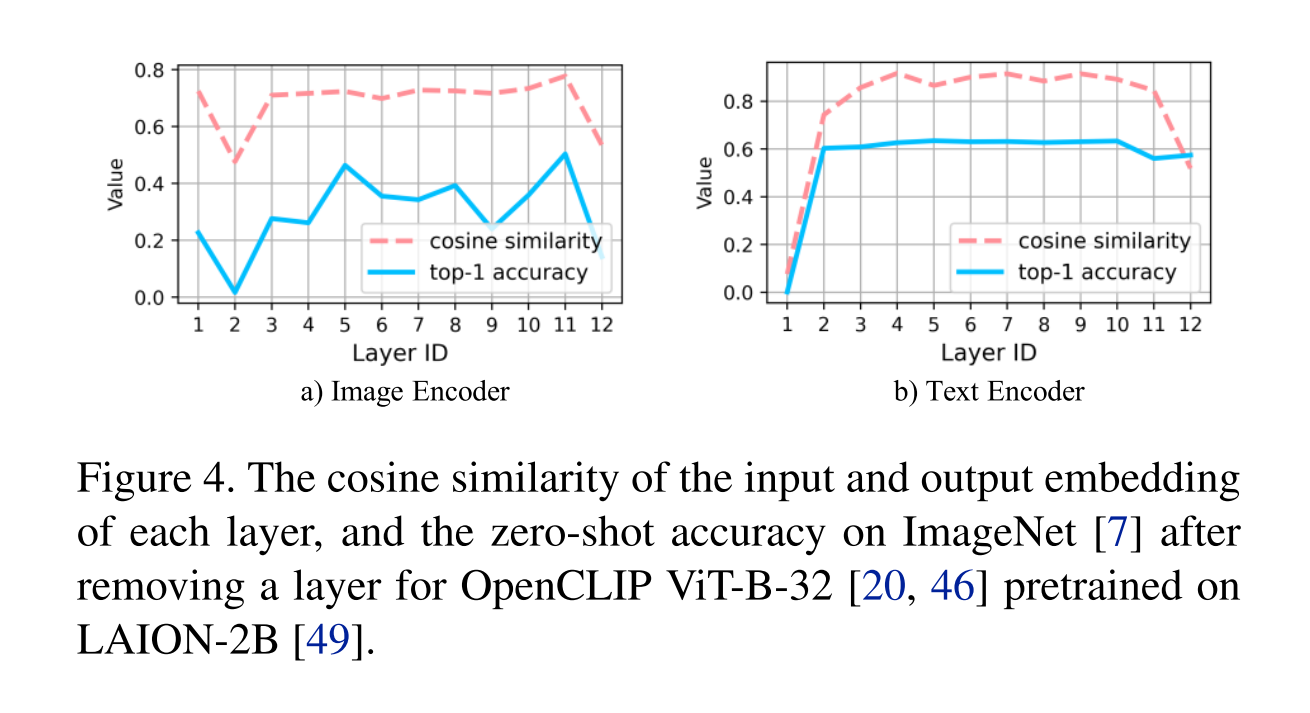
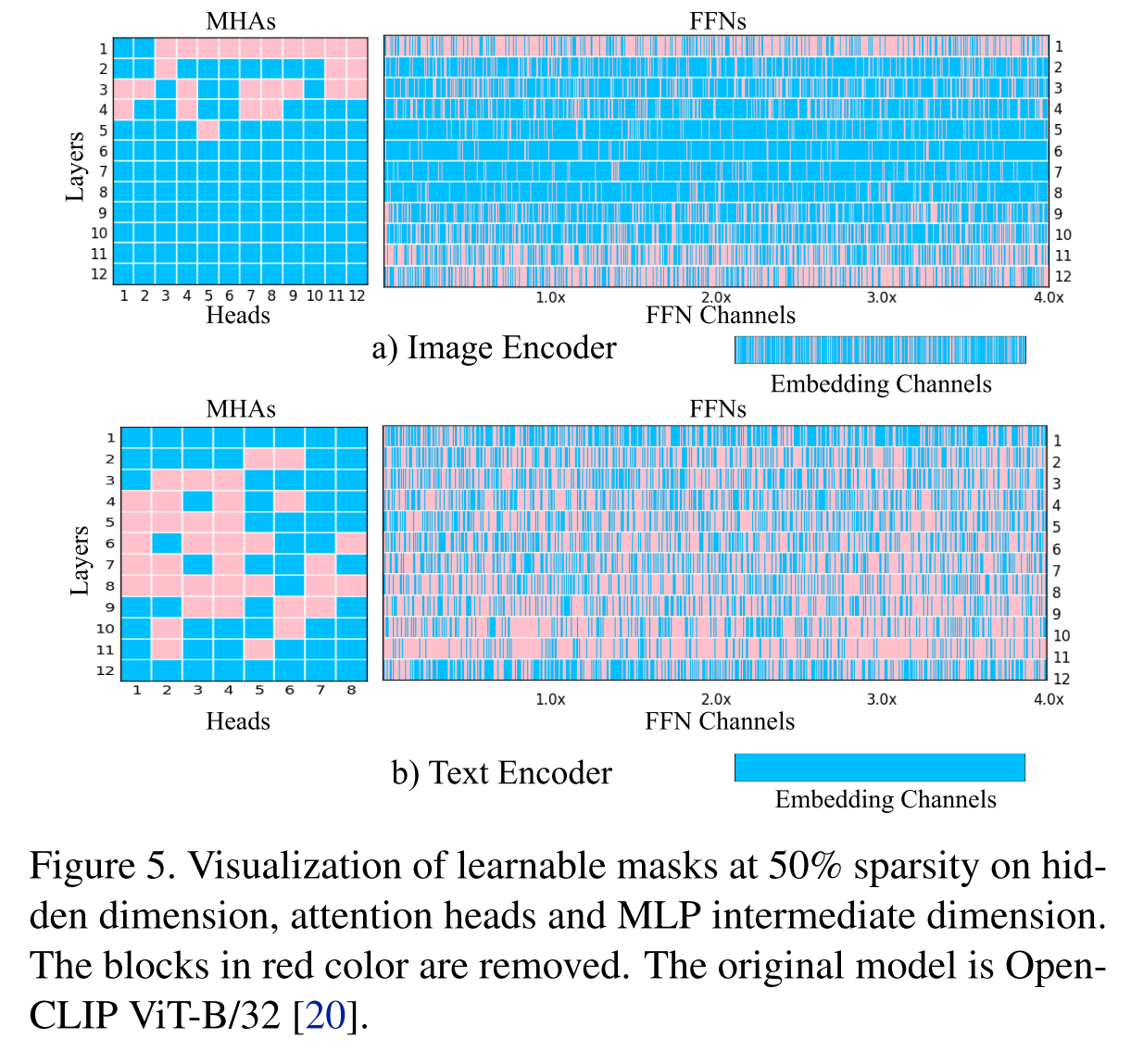
TinyCLIP: CLIP Distillation via Affinity Mimicking and Weight Inheritance ICCV23
说实话训练方法我没怎么看懂
主要目的
提出了一种新的跨模态蒸馏方法,用于大规模语言图像预训练模型。亲和力模仿探索在蒸馏过程中模态之间的相互作用,使学生模型能够模仿教师在视觉语言亲和力空间中学习跨模态特征对齐的行为。
经验
1.从教师模型中简单地手动选择k维或k层权重可以为CLIP蒸馏产生令人满意的结果。
2.将继承分为多个阶段,允许每个阶段的学生模型与前任教师共享更相似的结构,并逐步继承权重。
效果