视频检索
Video Retrieval
Space-Time Attention(基本框架 ICML 2021:happy:)
Is Space-Time Attention All You Need for Video Understanding?
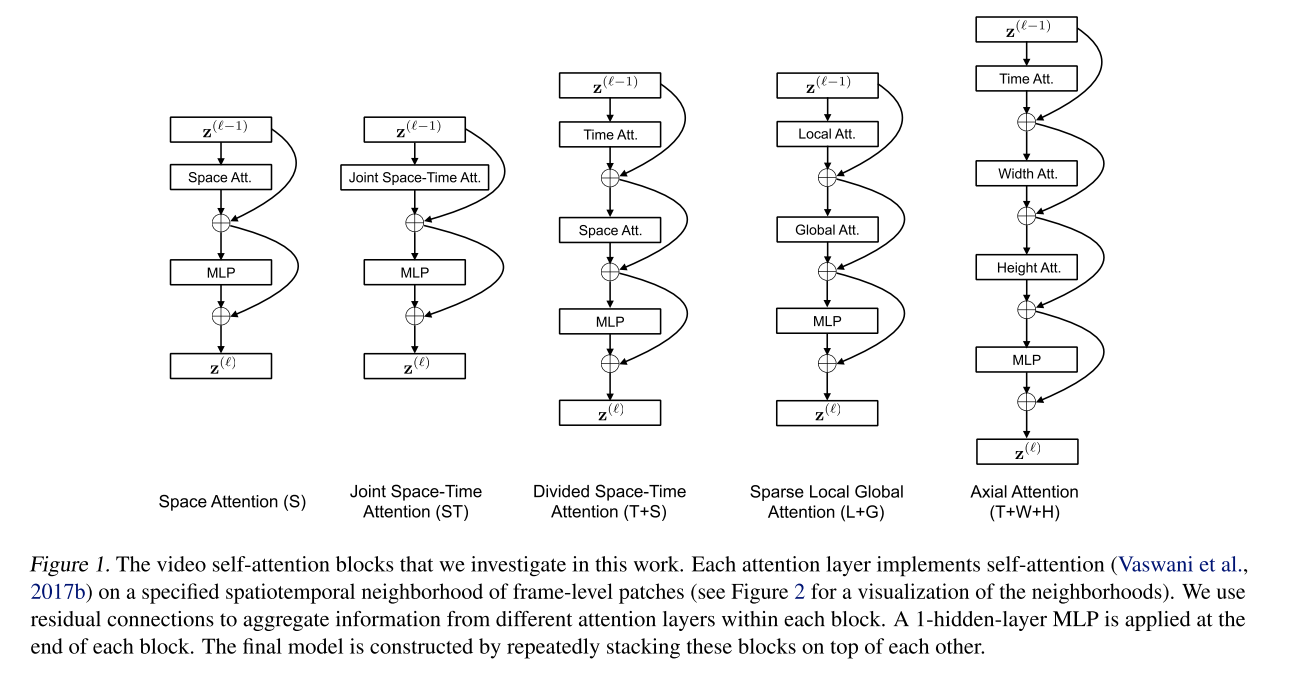
- 直接将Attention应用到图片的方法迁移到视频之中(空间注意力)
- 在时间上和空间上分别做三个自注意力机制,进行融合
- 拆分为空间和时间上分别进行注意力机制计算(时间-> 空间)文章提出
- local global拆分(在局部进行注意力计算)
- 沿着特定的轴进行注意力计算(将三维拆分为三个一维进行注意力机制计算)

想法简单、效果好、容易迁移、可以用于处理超过1min的视频
CLIP4Clip(2021 :happy:)
An Empirical Study of CLIP for End to End Video Clip Retrieval
背景:CLIP模型的提出,探究图像特征是否足够用于视频-文本检索、对视频帧之间的时间依赖性建模的实用机制是什么?
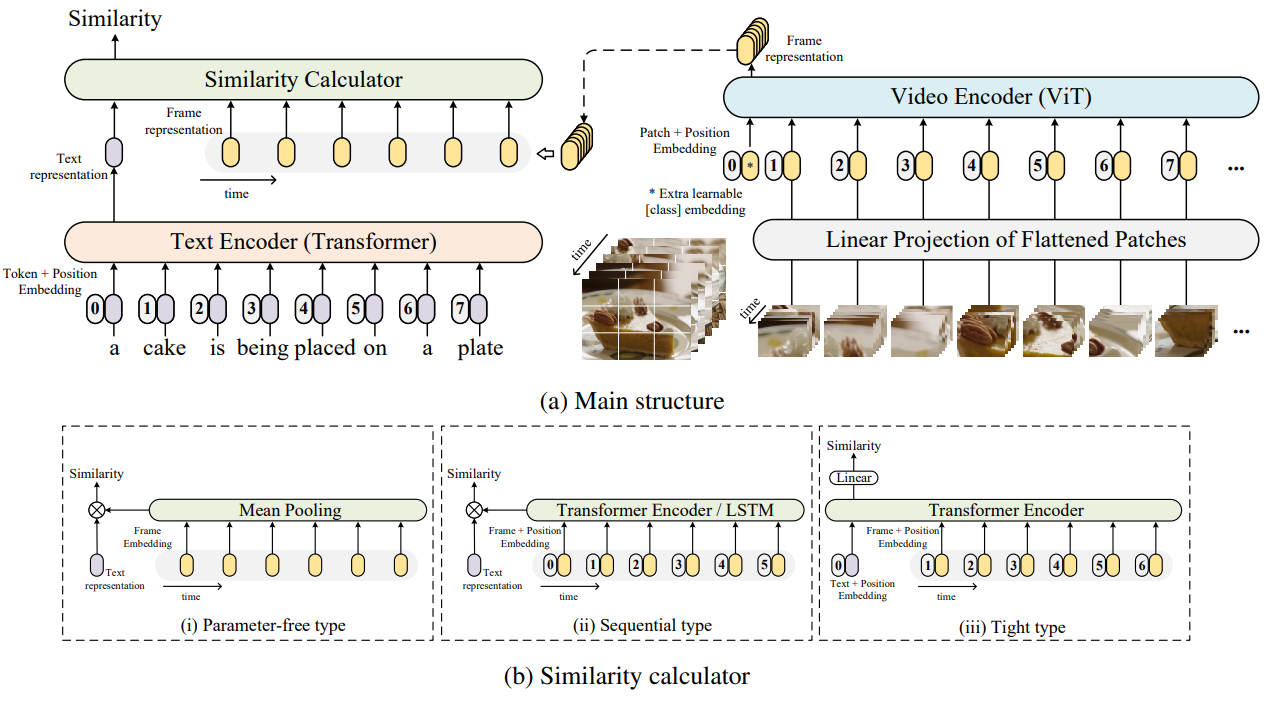
FT(ICCV 2021)
Frozen in Time: A Joint Video and Image Encoder for End-to-End Retrieval
工作:视频和文本的联合嵌入,旨在利用大规模图像和视频字幕数据集。可用于图像和视频,可以处理不同长度的输入,提出了新的数据集
损失函数: InfoNCE
X-Pool(CVPR 2022)
Cross-Modal Language-Video Attention for Text-Video Retrieval
背景:视频和文本信息不对等,文本通常捕获整个视频的子区域,并且在语义上与视频中的某些帧最为相似。
工作:选择与文本相关的文本Token相近的视觉Token,不直接挑选Top-K而直接注意力软性选择
损失: InfoNCE
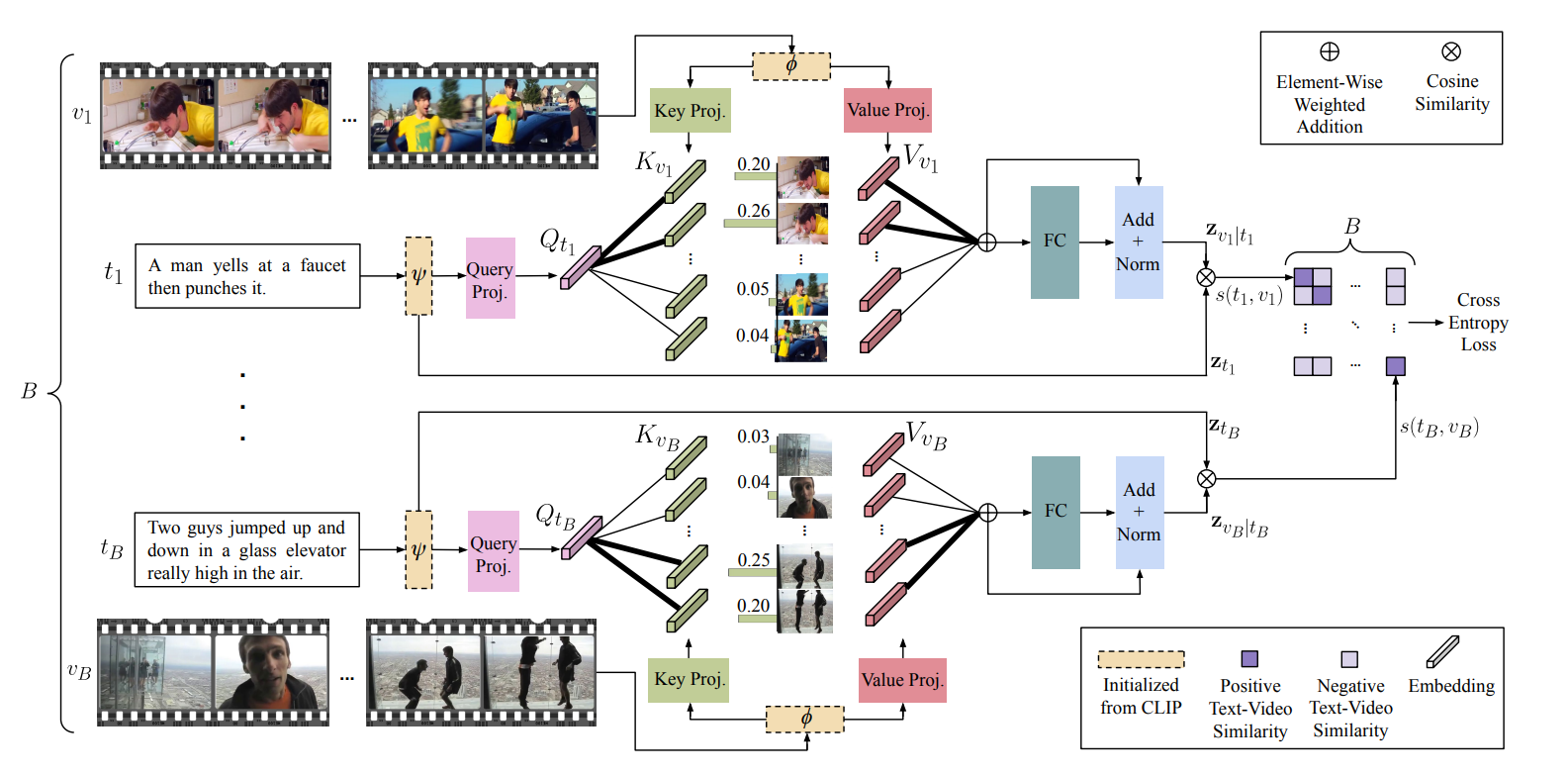
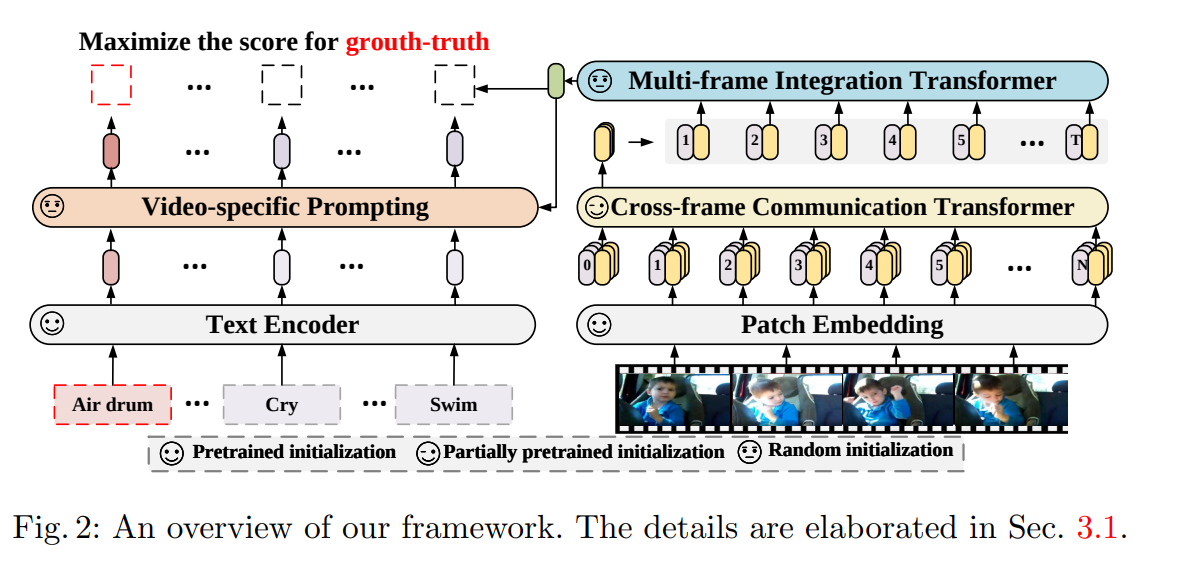
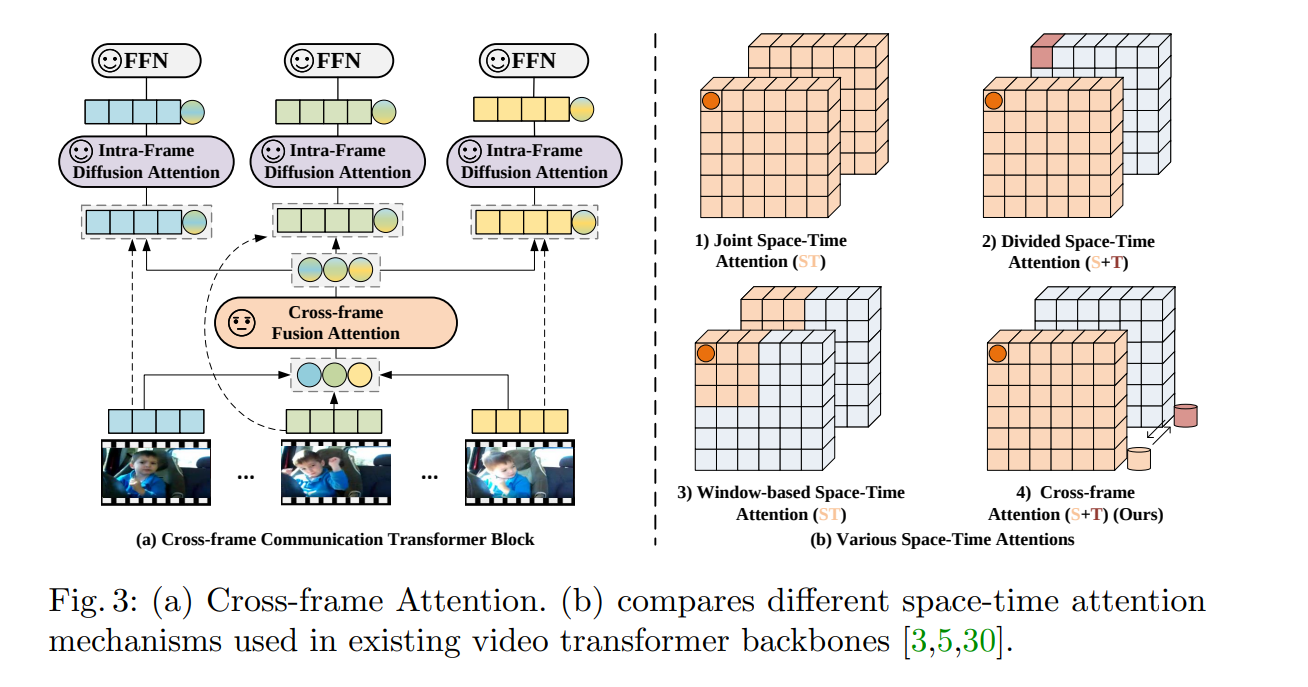
X-Clip(ECCV 2022 :happy:)
Expanding Language-Image Pretrained Models for General Video Recognition
背景:CLIP很好用,要将语言 - 图像预训练模型拓展到通用视频识别的方法;还有如何利用视频类别标签中的文本信息
工作:时间维度融合的新方法,先融合到时间维度再利用融合后的特征返回和图像维度融合;视频自适应的提示学习
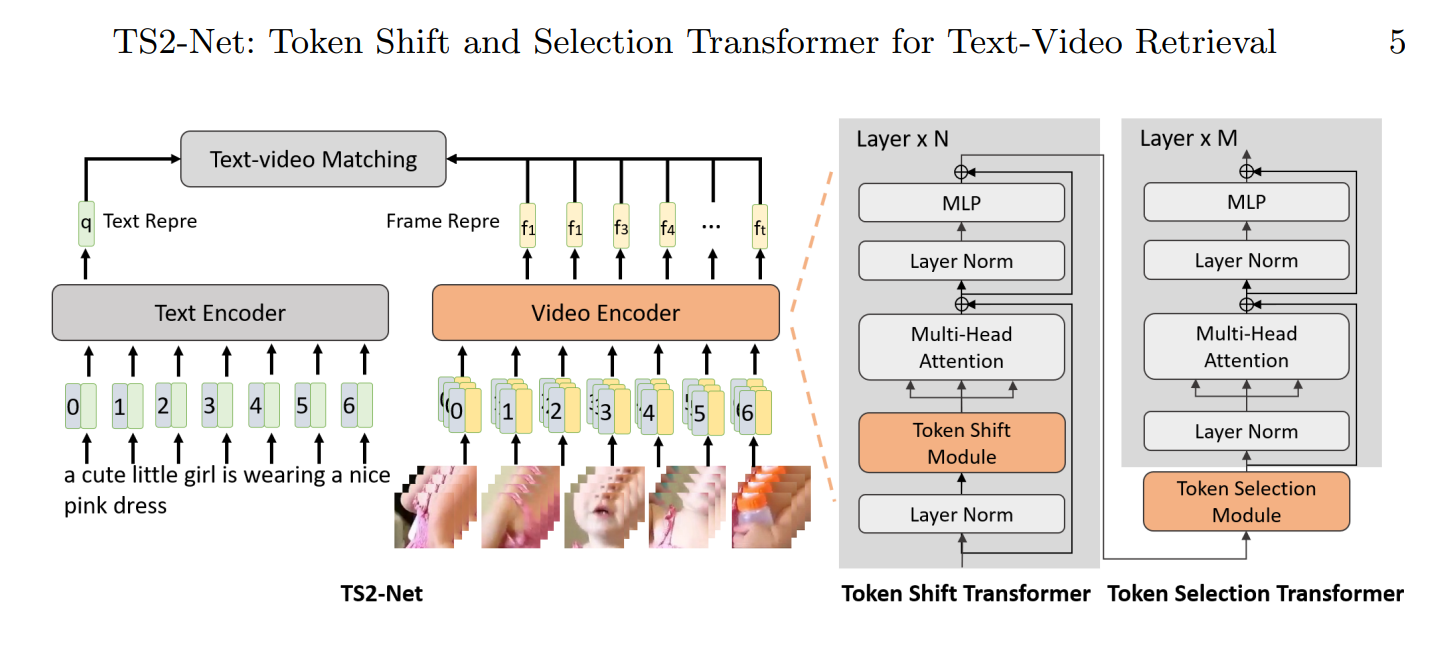
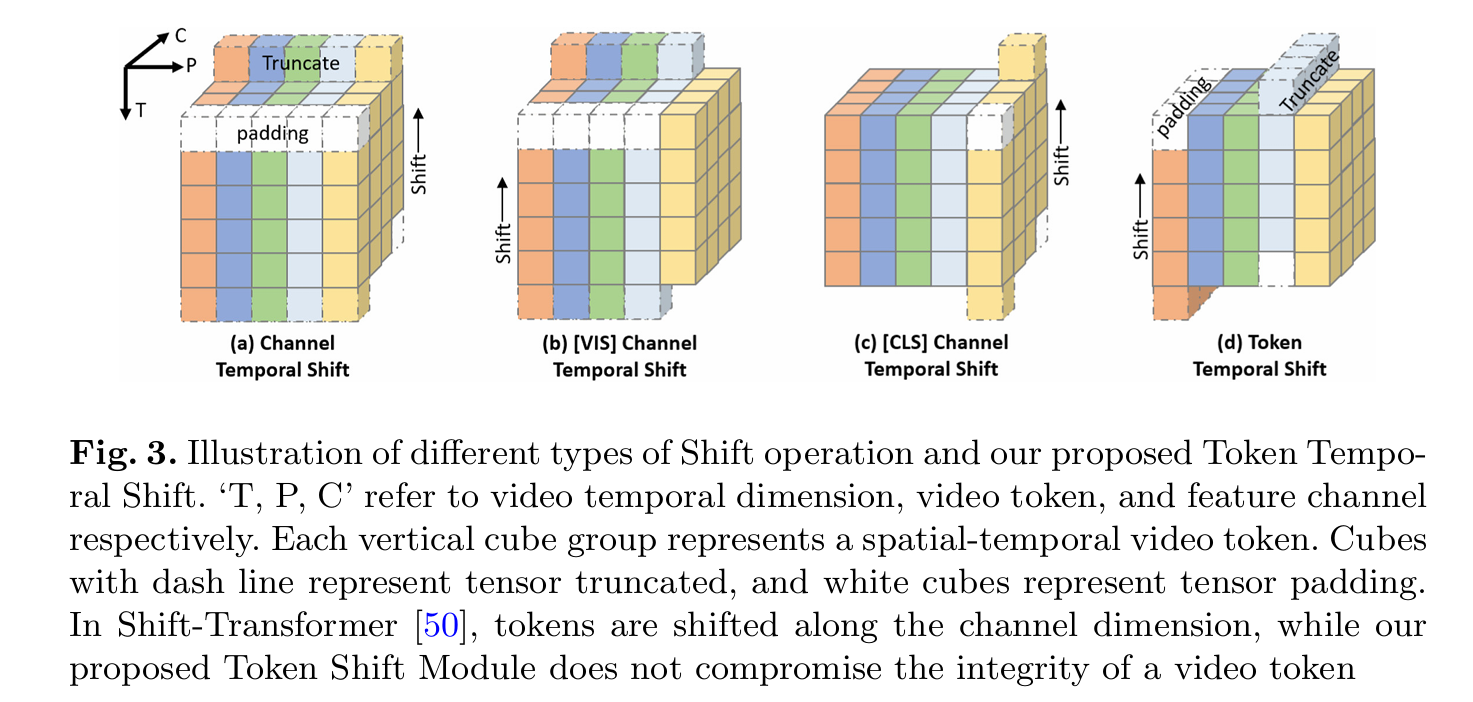
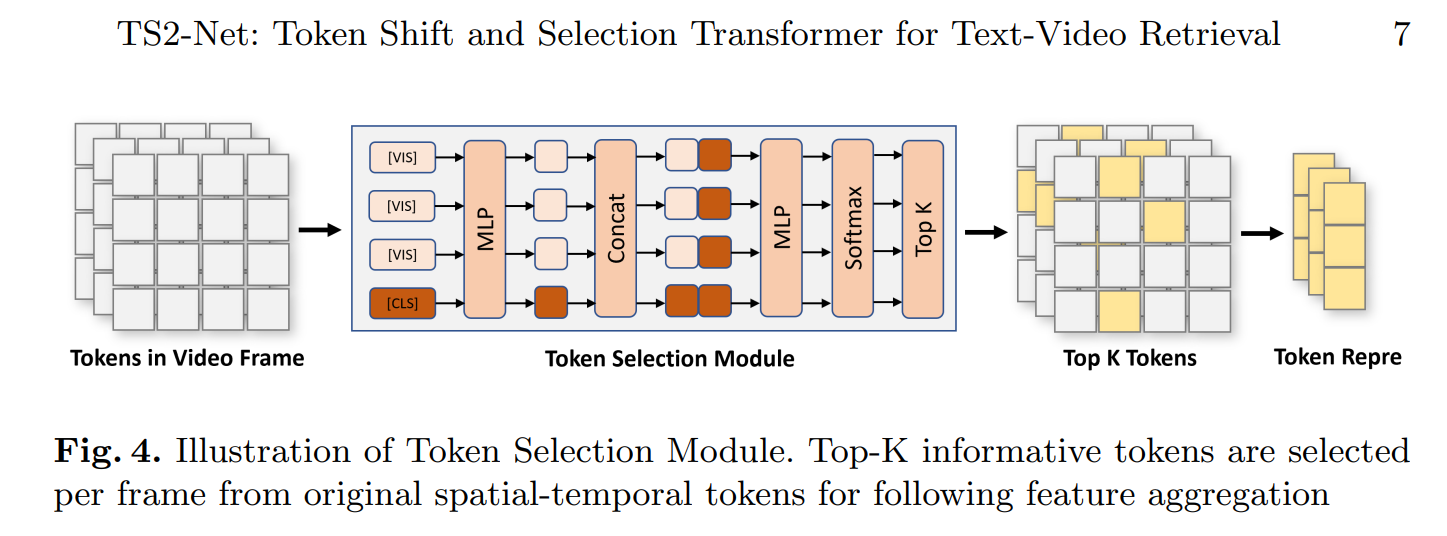
TS2-Net(ECCV 2022)
TS2-Net: Token Shift and Selection Transformer for Text-Video Retrieval
背景:现有的框架都是预训练,对细粒度的时空视频表示学习不太好
工作:时间维度融合,利用Token之间的平移捕捉变动差别;通过Token的选择好的Token同时减少计算量
损失:InfoNCE
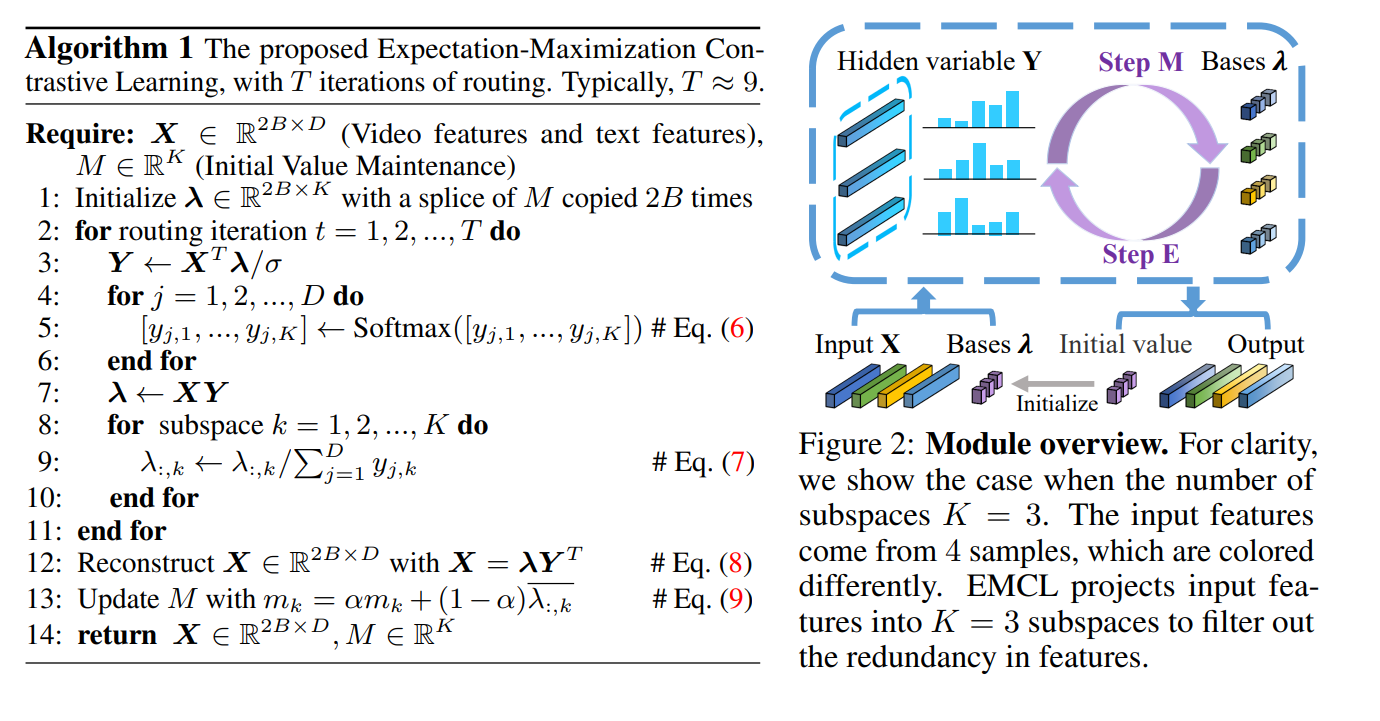
EMCL(NeurIPS 2022)
Expectation-Maximization Contrastive Learning for Compact Video-and-Language Representations
背景:视频和文本的嵌入空间之间的差距无法消除
工作:利用EM算法优化嵌入空间
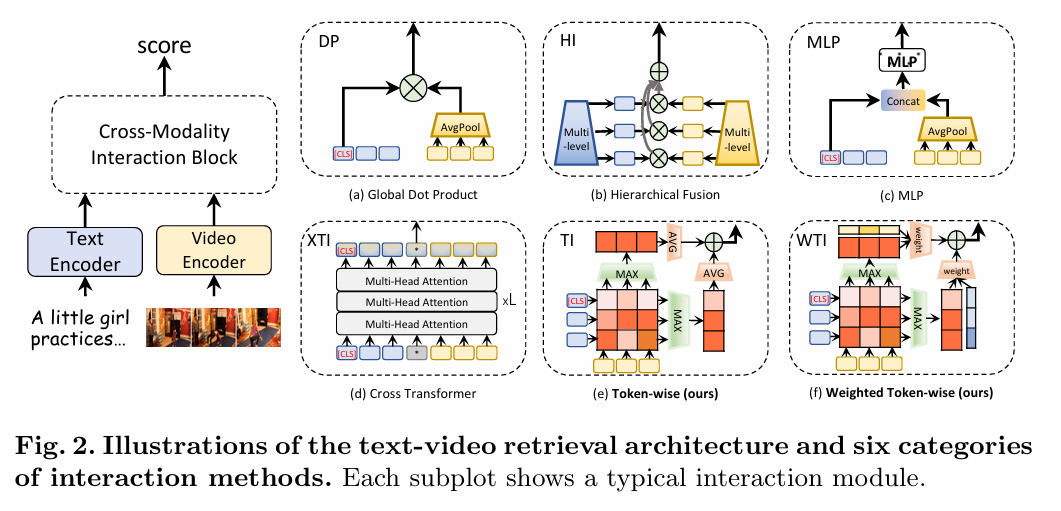
DRL(技术报告 2022)
Disentangled Representation Learning for Text-Video Retrieval
背景:很少有人对模态间的交互进行研究
工作:出了一个分离的框架来捕获顺序和层次表示。WTI适应性生成相关度,CDCR减低冗余度

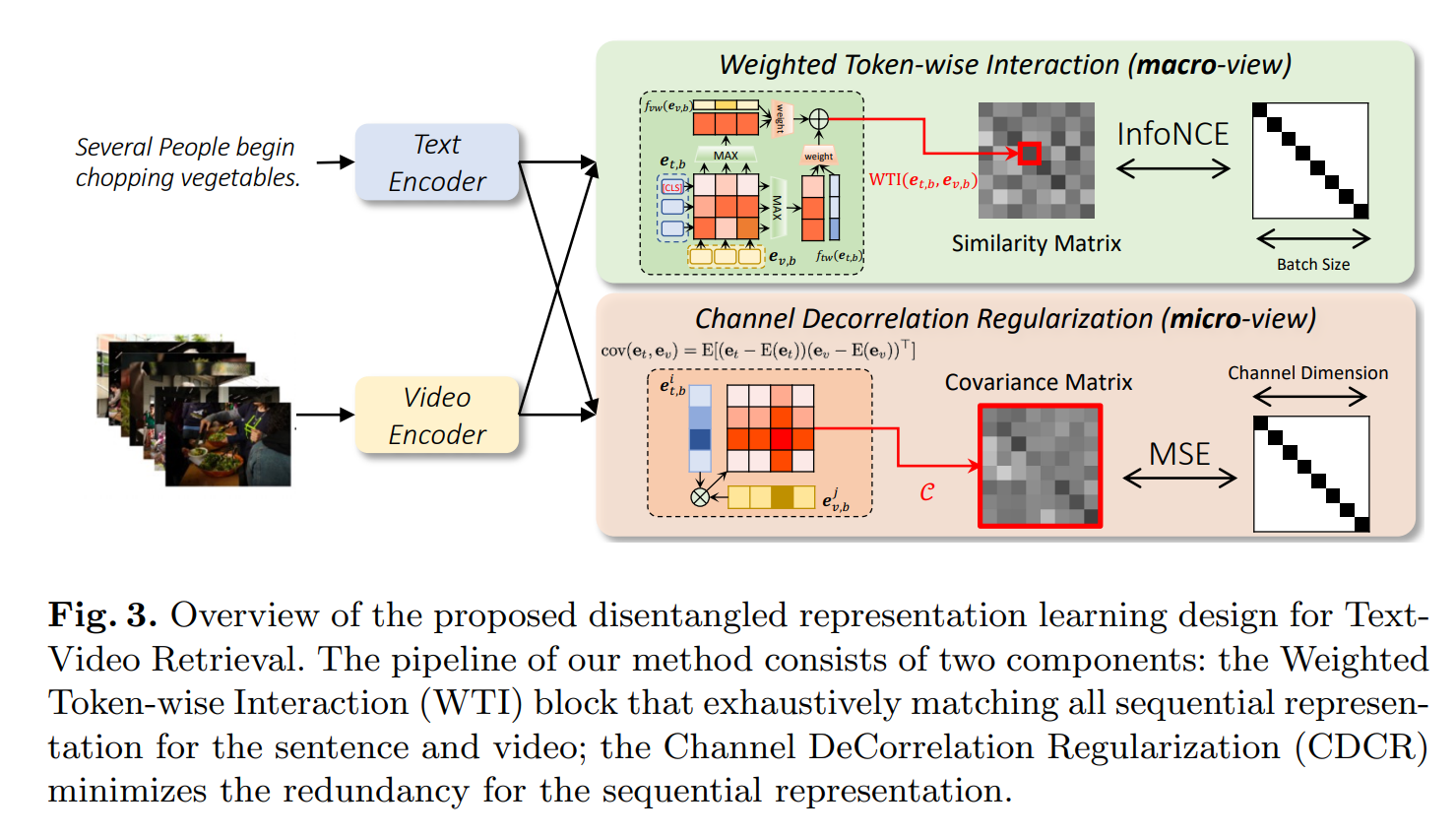
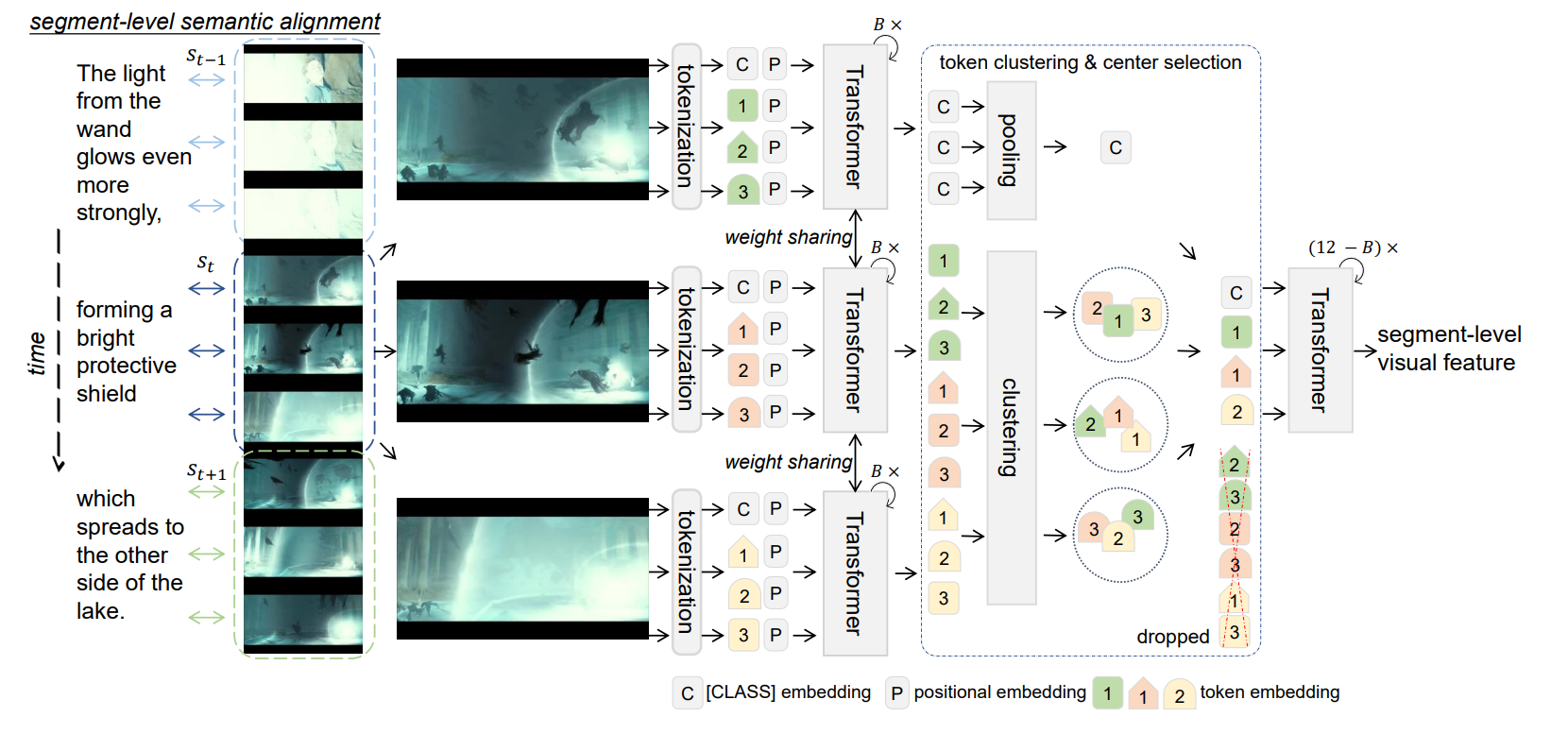
CenterCLIP(SIGIR 2022)
Token Clustering for Efficient Text-Video Retrieval
背景:在视频的提取中有连续和相似帧的冗余
工作:减少冗余Token,设计不同的聚类算法,有效聚类

去除冗余信息
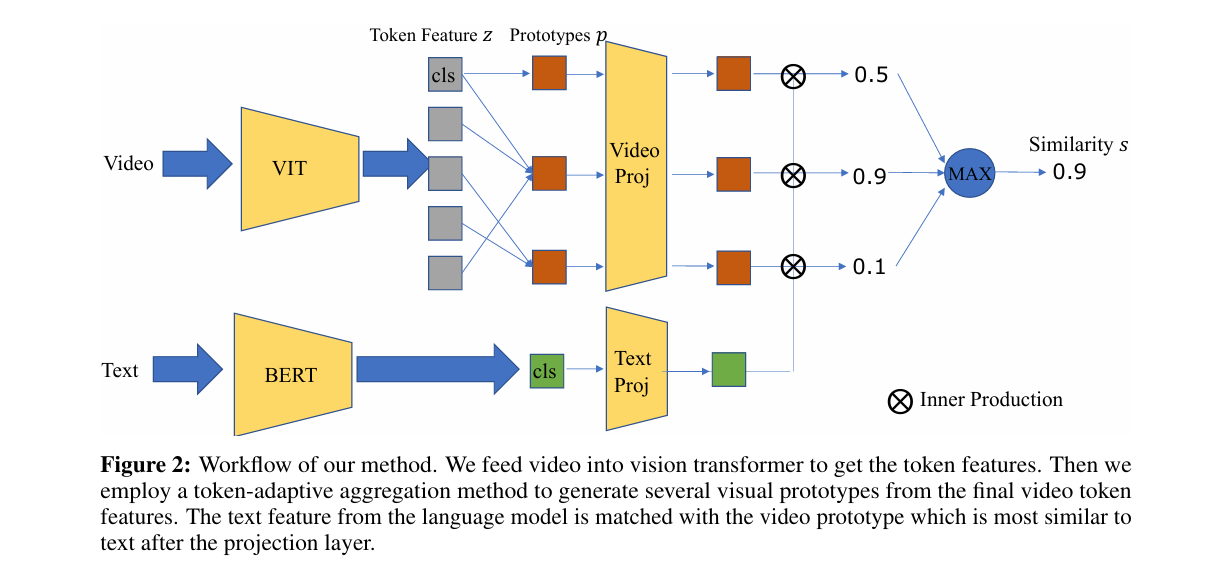
TMVPM(NIPS 2022)
Text-Adaptive Multiple Visual Prototype Matching for Video-Text Retrieval
背景:视频信息多,文本信息少,需要缓解视频和文本对应的歧义问题
工作:自适应地聚合视频标记特征来自动捕获多个Prototype来描述视频,进行文本的自适应匹配
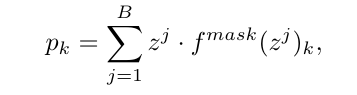
CLIP-bnl(ACMMM 2022)
Learn to Understand Negation in Video Retrieval
背景:常见的模型对于否定的查询关注度低,导致检索效果不好
工作:提出了构建否定数据集的新方法,提出了新的数据集

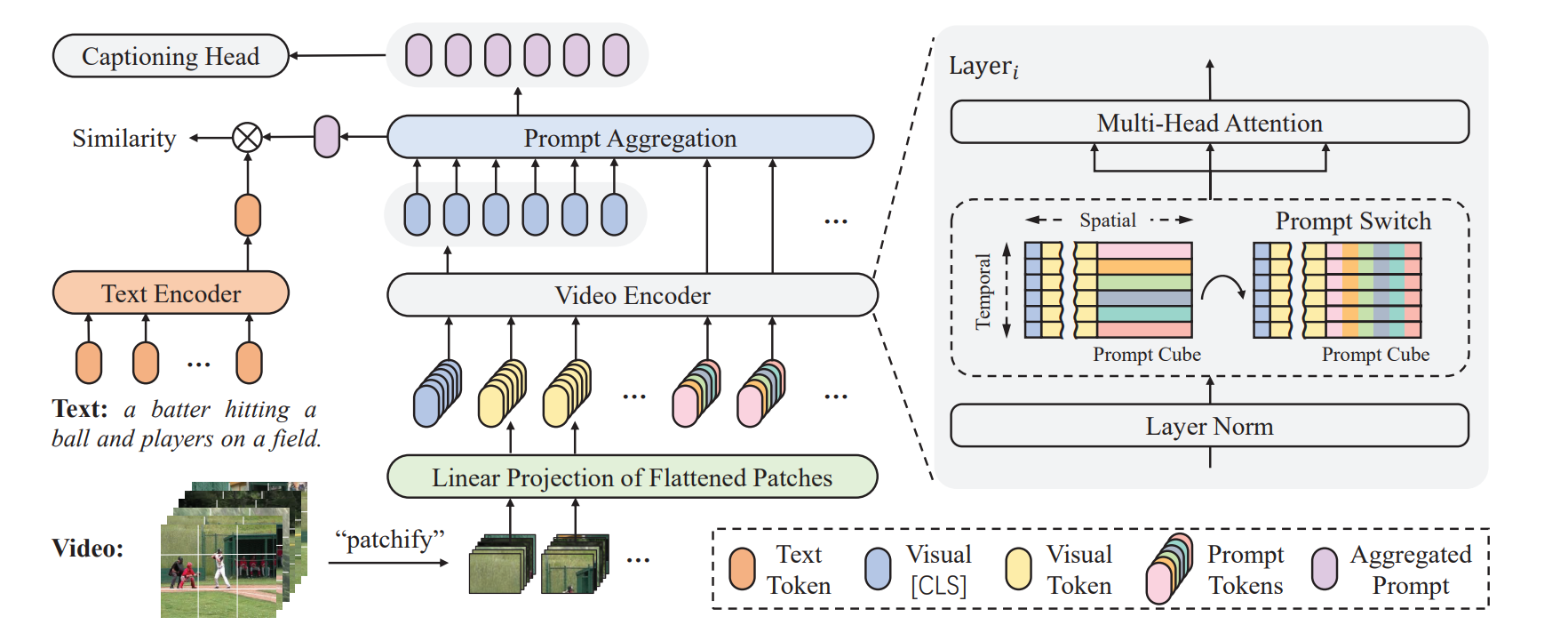
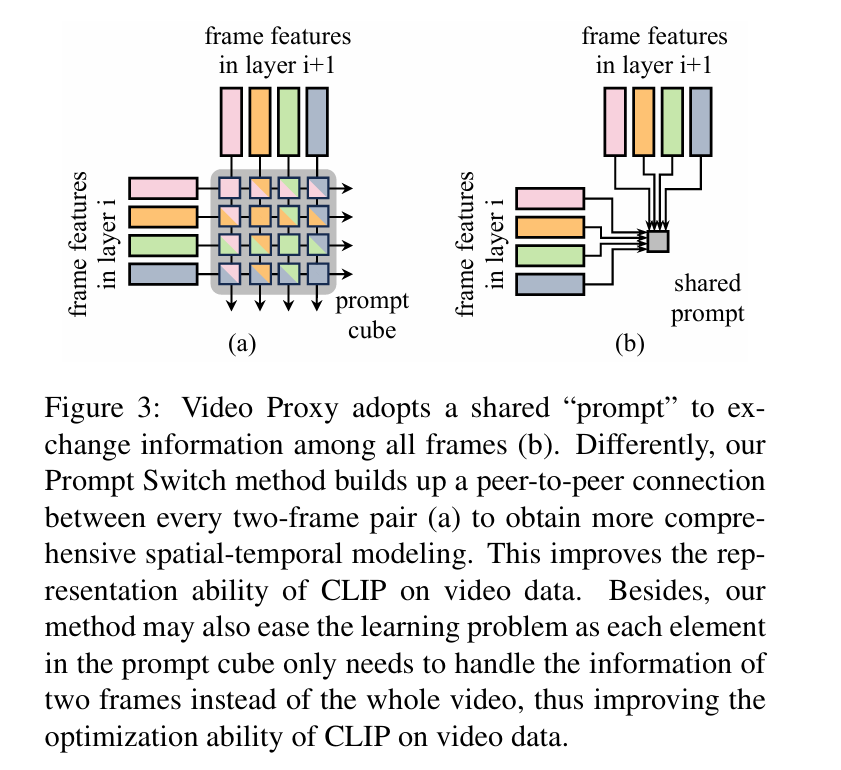
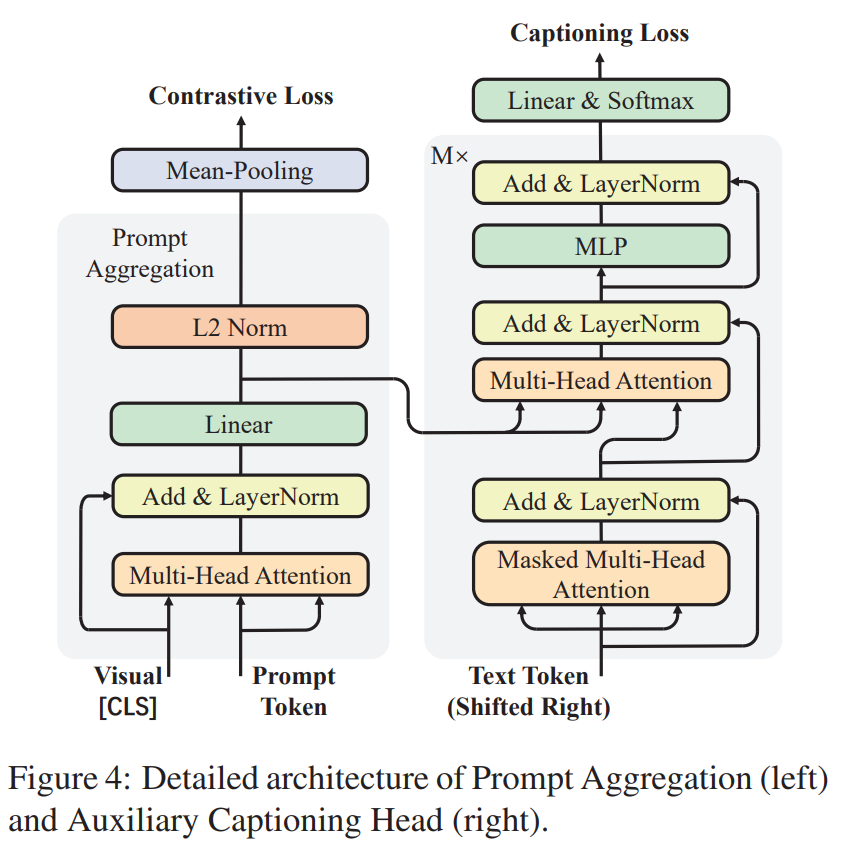
Prompt Switch(ICCV 2023)
Prompt Switch: Efficient CLIP Adaptation for Text-Video Retrieval
背景:如何使用CLIP捕捉视频中的丰富的语义,而将文本融合到图像中效率低
工作:引用时空Prompt Cube 将青荃路视频语义融合到帧表示中
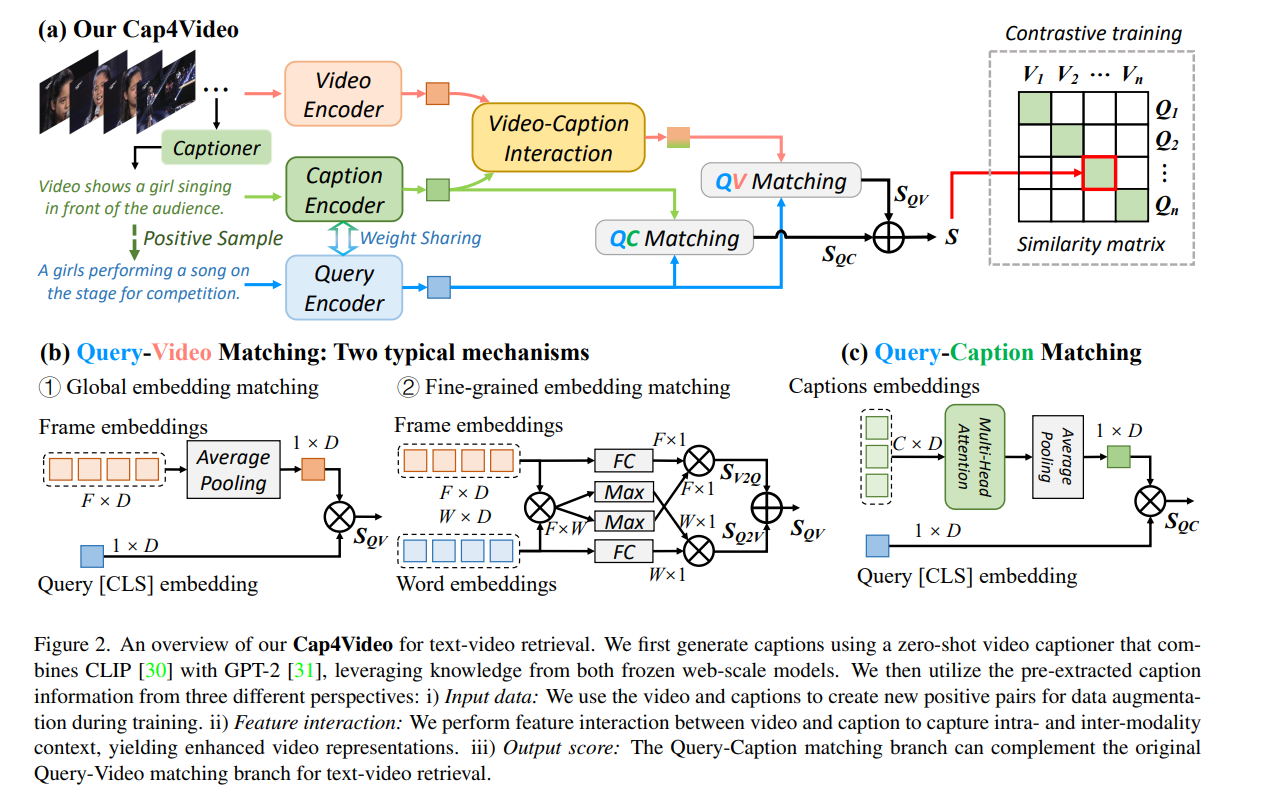
Cap4Video(CVPR 2023)
Cap4Video What Can Auxiliary Captions Do for Text-Video Retrieval
背景:现在的检索,只考虑Query文本,在现实世界的场景中,在线视频往往伴随着相关的文本信息,
工作:利用额外的文本信息增强视频表示
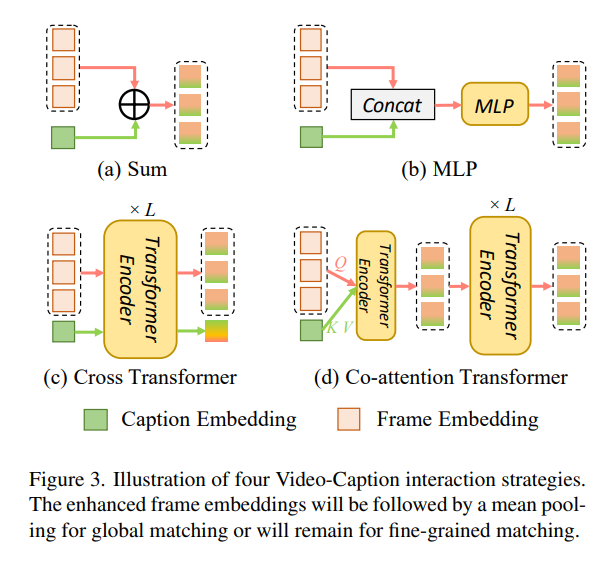
UATVR(ICCV 2023 :happy:)
UATVR: Uncertainty-Adaptive Text-Video Retrieval、
背景:目前对于跨模态的检索,往往把他们嵌入到相同的空间,但是由于信息量不对等,无法自适应汇聚多粒度语义
工作:粗细粒度的偏重就有不确定性,本文针对这一问题,将视频文本表示为概率分布,提出了不确定性的自适应检索方法
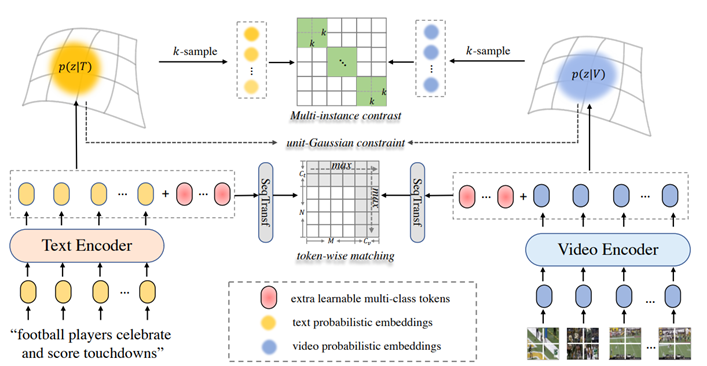
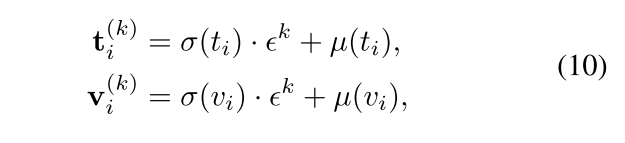
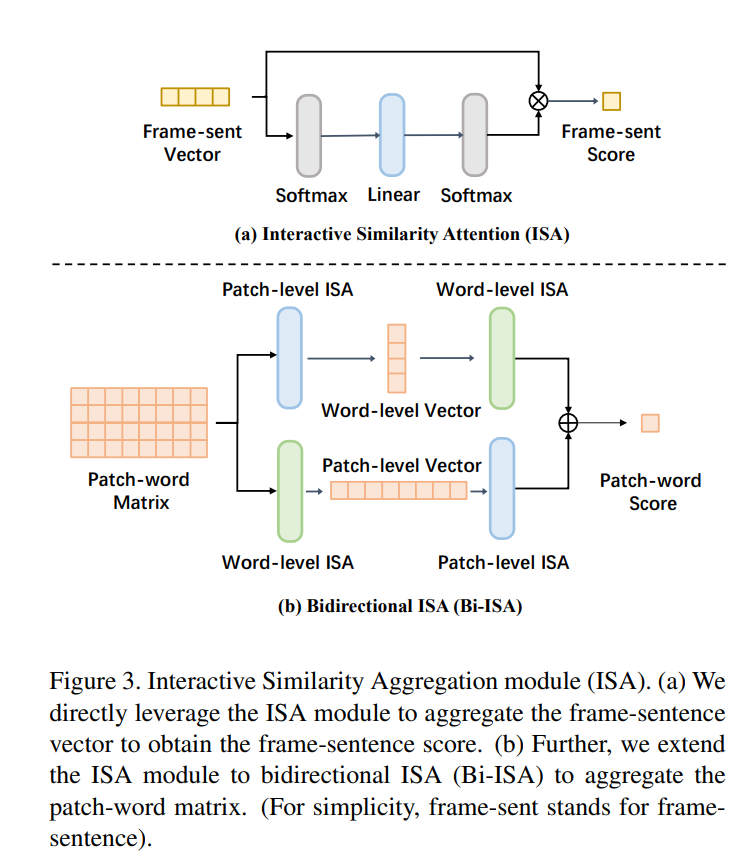
UCOFIA(ICCV 2023)
Unified Coarse-to-Fine Alignment for Video-Text Retrieval
背景:觉信息和文本信息之间的粗粒度或细粒度对齐之间的规范不明
工作:如何规范的利用视频和文本进行粗细粒度对齐,ISA减轻不想关信息的影响
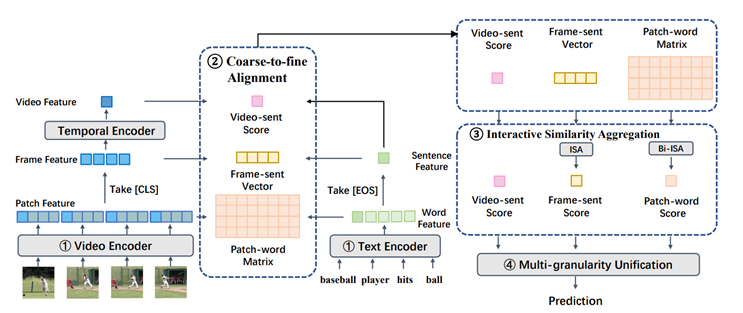
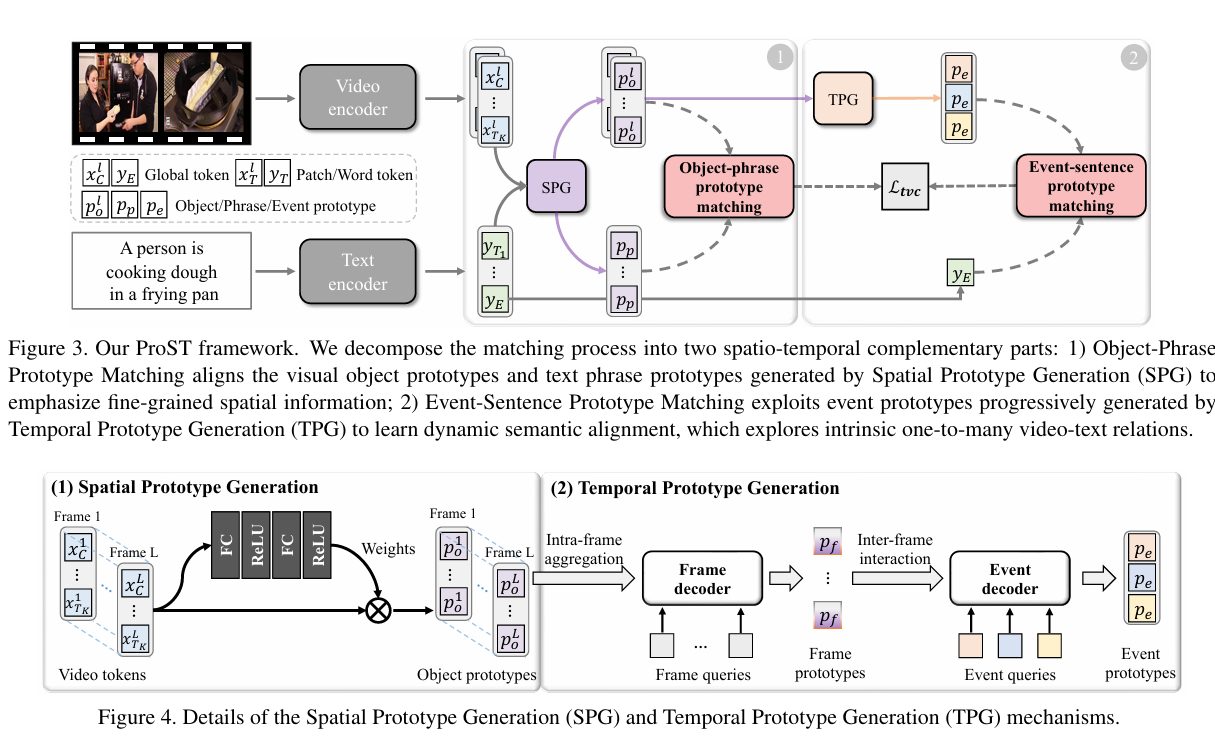
ProST(ICCV 2023)
Progressive Spatio-Temporal Prototype Matching for Text-Video Retrieval
背景:还是视频和文本信息不对等,常见的方法视频与文本之间的内在关系,即文本描述只对应于视频的时空部分。匹配过程应该同时考虑细粒度的空间内容和各种时间语义事件。
工作:将匹配的过程拆分成了短语原型匹配和事件匹配

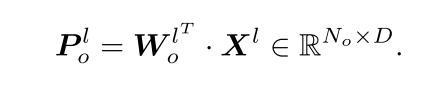
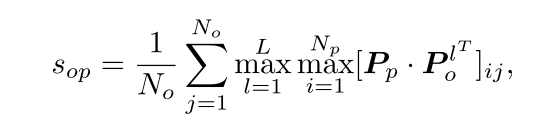

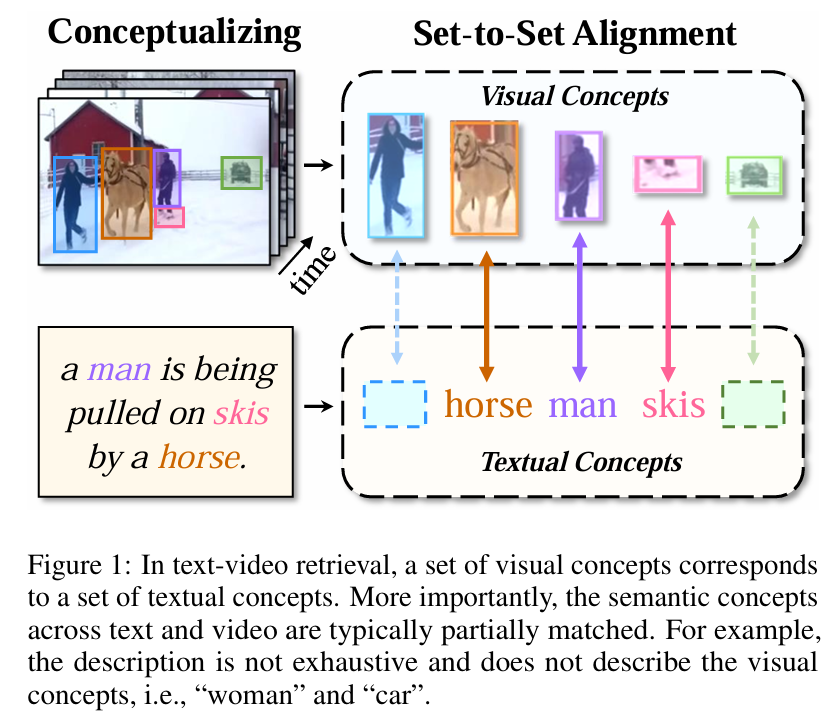
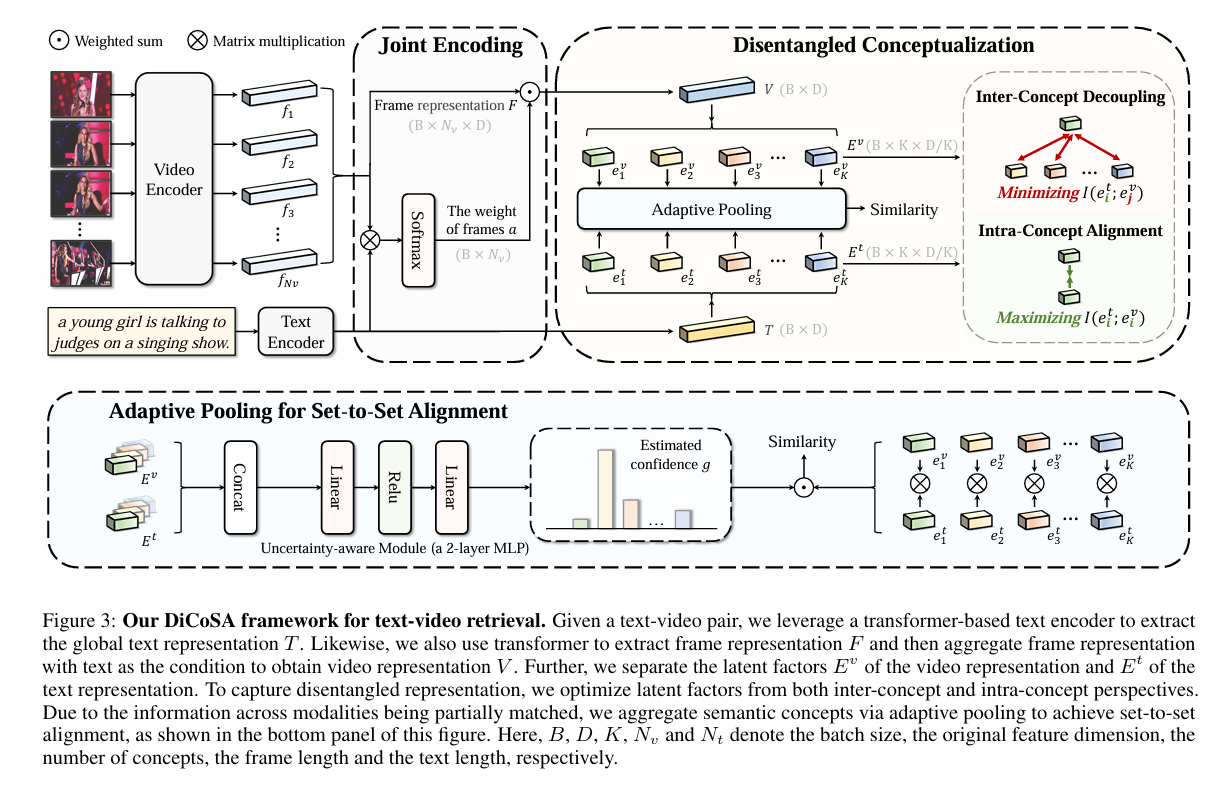
DiCoSA(IJCAI 2023)
Text-Video Retrieval with Disentangled Conceptualization and Set-to-Set
背景:视频和文本细粒度对齐框架不好用
工作:一种自适应汇集方法来聚合语义概念以解决部分匹配问题,在几个维度设置独立编码

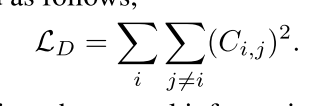
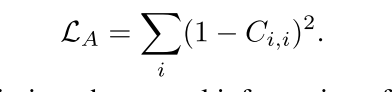
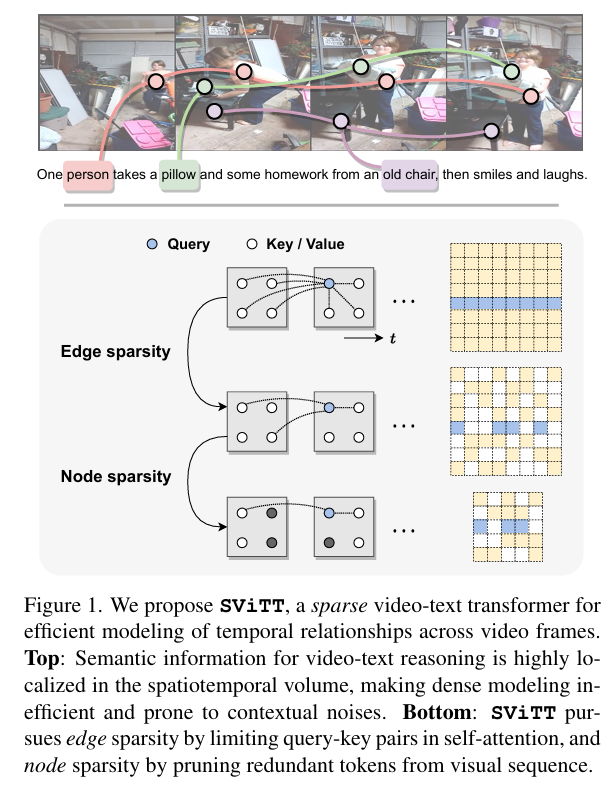
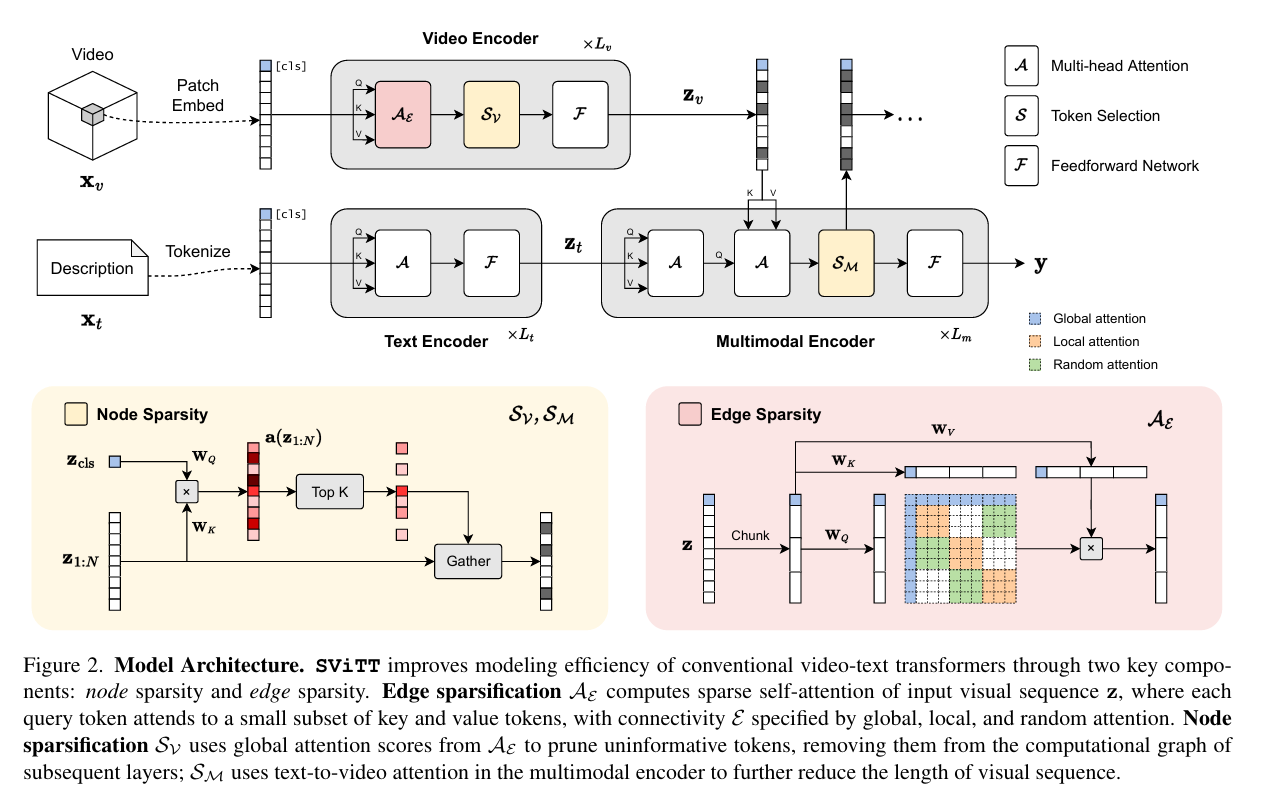
SViTT(CVPR 2023)
SViTT: Temporal Learning of Sparse Video-Text Transformers
背景:视频文本检索需要平衡时空建模的开销,和帧数的控制
工作:一种执行多帧推理的稀疏视频-文本体系结构,其中文中边稀疏性是的是减少Token之间的相似度计算,点稀疏性指的是Token的数目
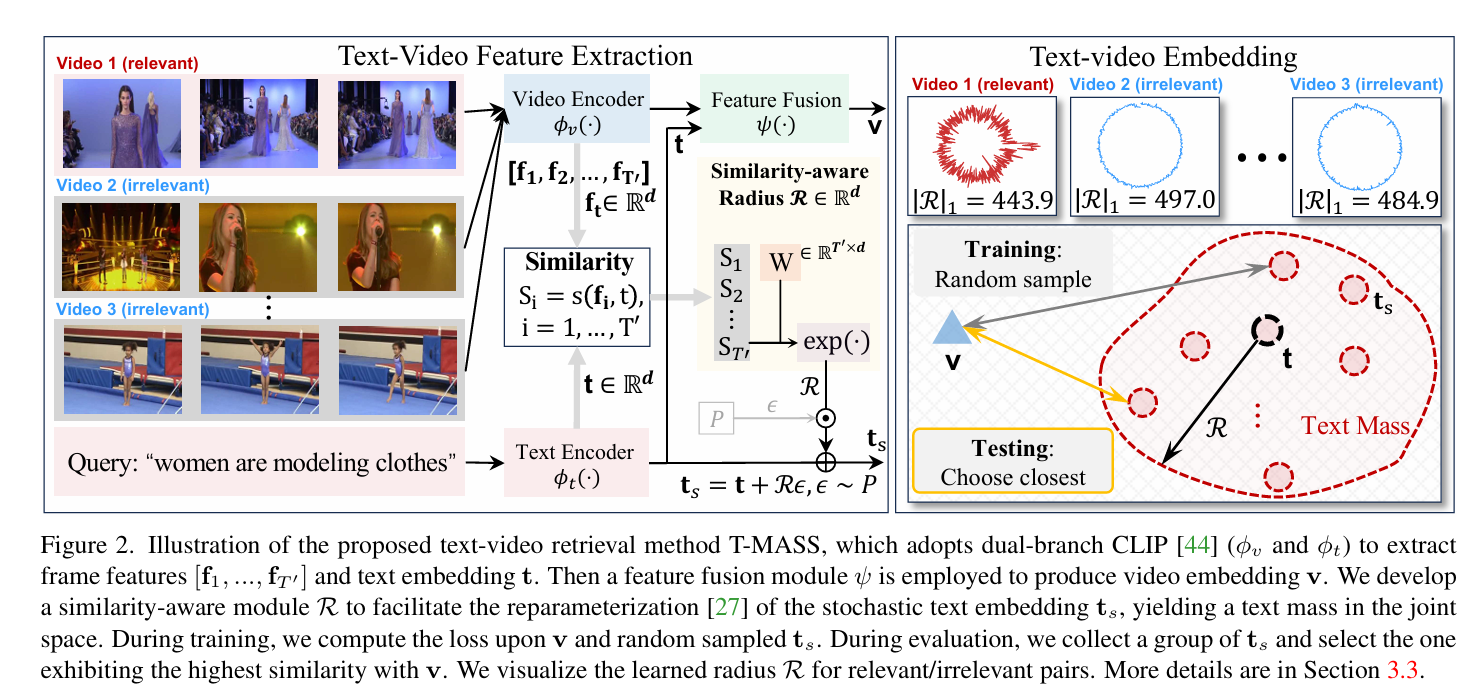
Text Is MASS(CVPR 2024:happy:)
Text Is MASS: Modeling as Stochastic Embedding for Text-Video Retrieval
背景:视频文本语义不对等,现有数据集中的文本内容一般都很简短,很难完全描述视频的冗余语义。
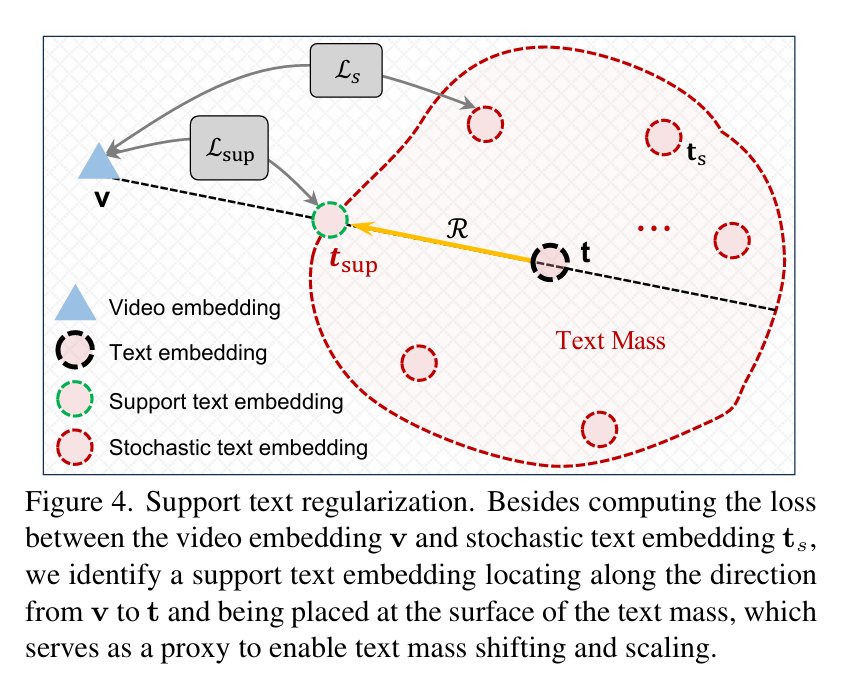
工作:提出了一种新的随机文本建模方法T-MASS,即将文本建模为随机嵌入,以丰富文本嵌入的灵活和弹性的语义范围,入了一个相似性感知半径模块来根据给定的文本-视频对来调整文本质量的大小。

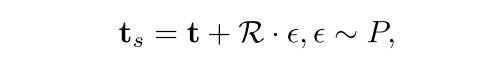
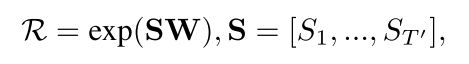
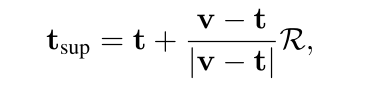
CLIP
A Picture is Worth More Than 77 Text Tokens: Evaluating CLIP-Style Models on Dense Captions(CVPR 2024)
A Picture is Worth More Than 77 Text Tokens: Evaluating CLIP-Style Models on Dense Captions
背景:即使是最高质量的精选字幕也太短了,无法捕捉到图像中丰富的视觉细节。
工作:我们收集了密集标题图像(DCI)数据集,

General Methods
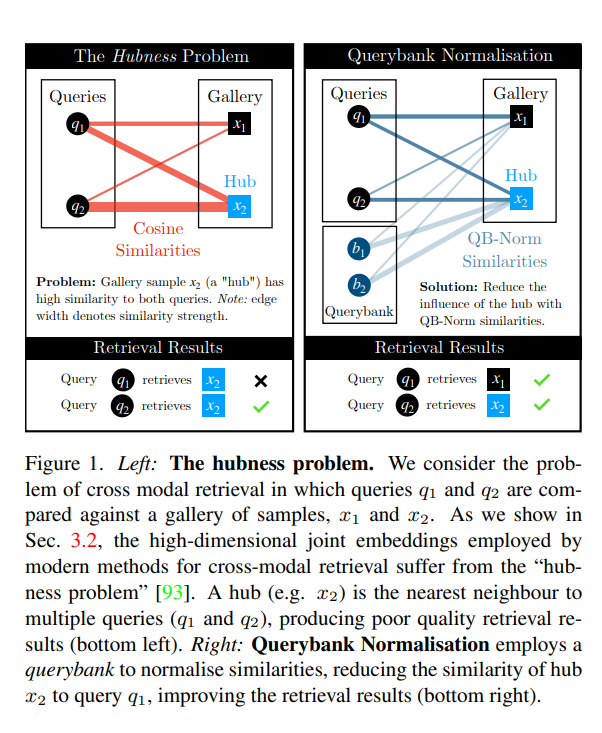
Cross Modal Retrieval with Querybank Normalisation(CVPR 2022)
Cross Modal Retrieval with Querybank Normalisation
主要解决的是检索中某一个样本对大部分相似度过高的情况