论文精读-DELL·E2-2022
前人工作
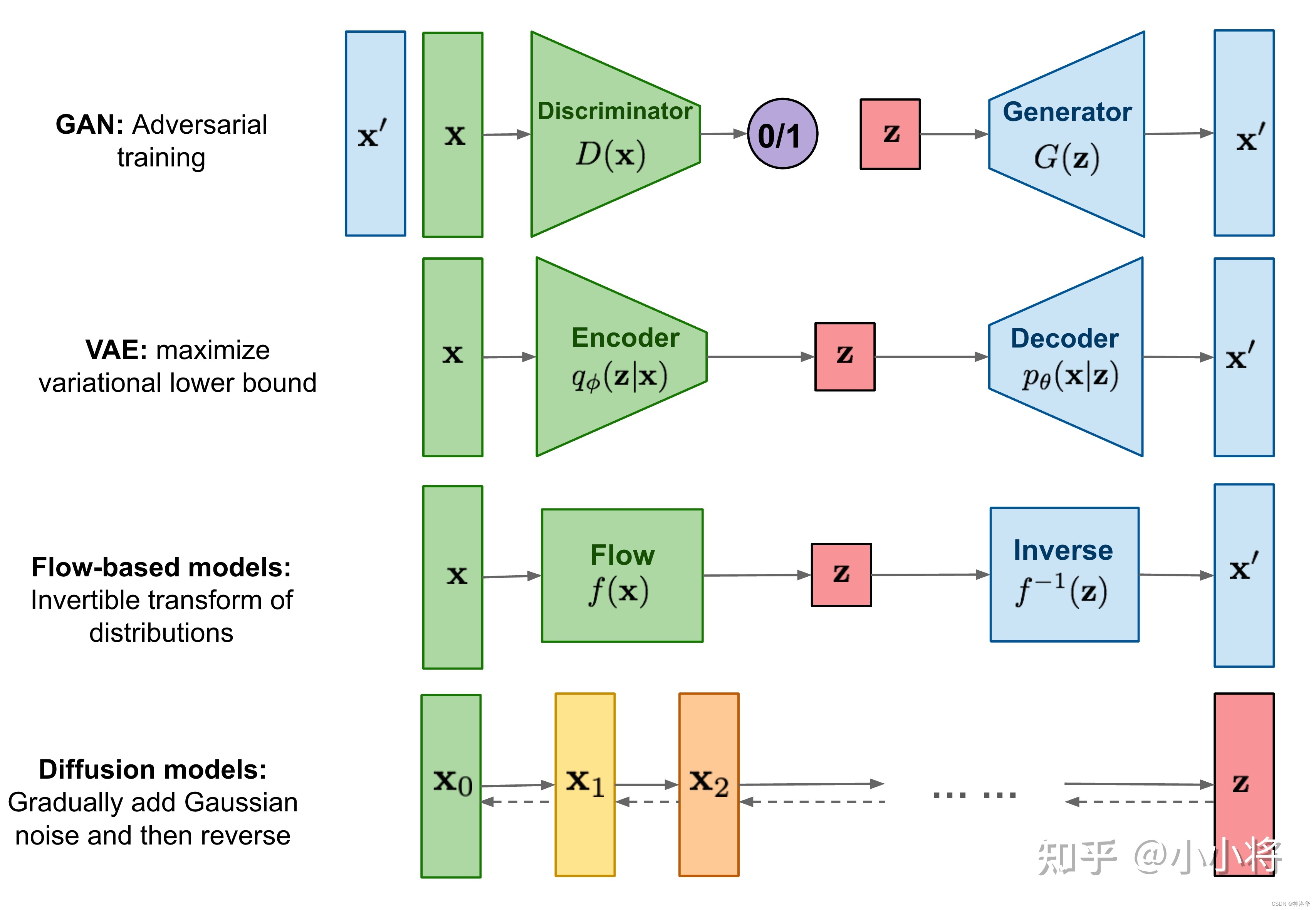
GANs
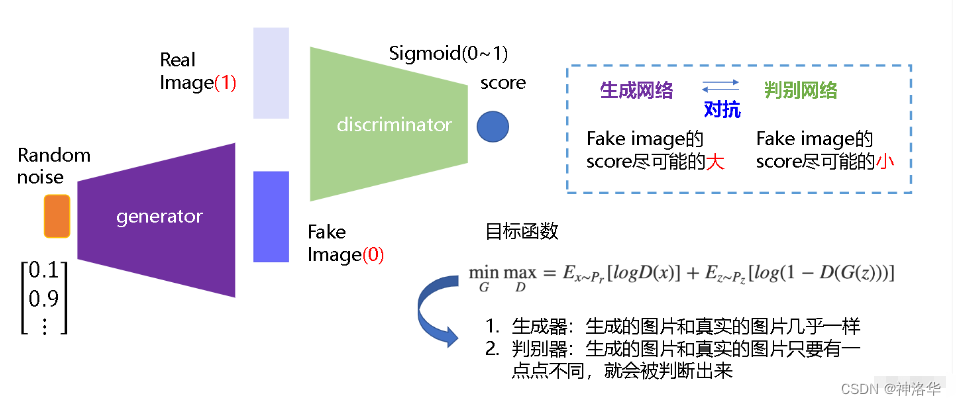
生成器G从给定噪声中(一般是指均匀分布或者正态分布)采样来合成数据,判别器D用于判别样本是真实样本还是G生成的样本。G的目标就是尽量生成真实的图片去欺骗判别网络D,使D犯错;而D的目标就是尽量把G生成的图片和真实的图片分别开来
局限性:
- 训练不够稳定
- GANs生成的多样性不够好
- GANs是隐式生成,不够优美
AE(Autoencoder)和 DAE(Denoising Autoencoder)
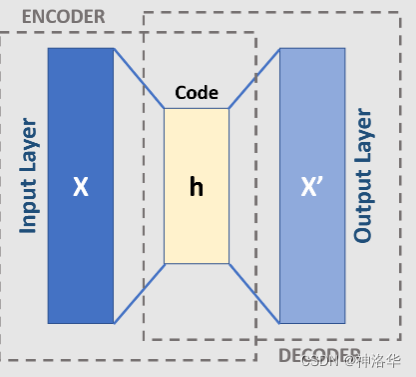
DAE(Denoising Autoencoder),就是先把原图$x$进行一定程度的打乱
VAE
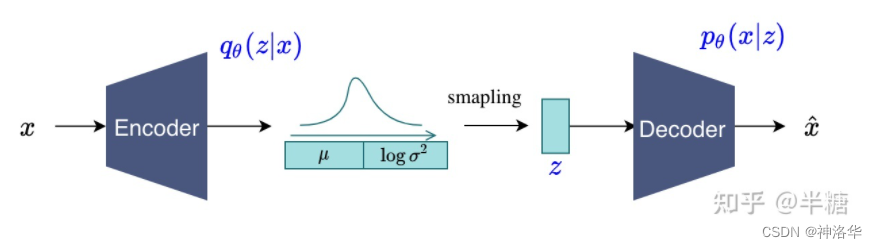
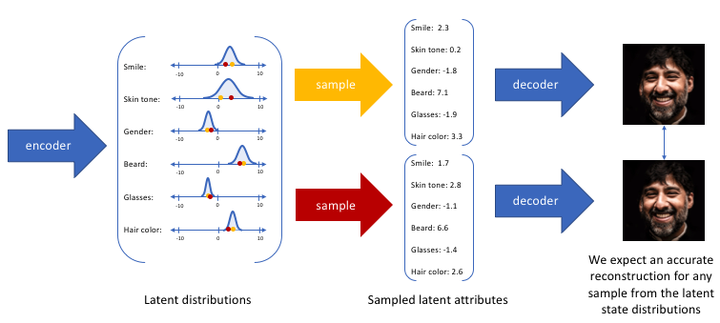
VAE(Variational Auto-Encoder-变分自编码器)就是借助了这种encoder-decoder的结构去做生成,和AE最主要的区别就是不再去学习中间的bottleneck特征了,而是去学习一种分布。
作者假设中间的分布是一个高斯分布(用均值μ 和方差σ 来描述)。具体来说,就是将输入x进行编码得到特征之后,再接一些FC层,去预测中间分布的μ 和σ 。
μ 和σ 训练好之后,就可以扔掉encoder了。推理时直接从训练好的分布去采样一些z 出来( $z=\mu +\sigma \cdot \varepsilon$),然后进行解码,这样VAE就可以用来做生成了
VQ-VAE
VQ-VAE
如果还是之前VAE的模式,就不好把模型做大,分布也不好学。取而代之的不是去直接预测分布z,而是用一个codebook代替。codebook可以理解为聚类的中心,大小一般是K*D(K=8192,Dim=512/768),也就是有8192个长为D的向量(聚类中心)
$x$输入编码器得到高宽分别为$( h , w )$ 的特征图f,然后计算特征图里的向量和codebook里的向量(聚类中心)的相似性。接着把和特征图最接近的聚类中心向量的编号(1-8192)存到矩阵z里面。训练完成之后,不再需要编码特征f ff,而是取出矩阵z中的编号对应的codebook里面的向量,生成一个新的特征图q(量化特征quantised feature)。最后和之前一样,使用q解码重构原图。此时这个量化特征就非常可控了,因为它们永远都是从codebook里面来的,而非随机生成,这样优化起来相对容易。
编码器输出$z ( x )$ 会mapped到最相近(nearest)的点$e 2$ 。红色线的梯度$\triangledown _{z}$L,迫使encoder在下一次forword时改变其输出(参数更新)
VQ-VAE也可以用来做CV领域的自监督学习,比如BEIT就是把DALL·E训练好的codebook拿来用。将图片经过上面同样的过程quantise成的特征图作为ground truth,自监督模型来训练一个网络。后续还有VL-BEIT(vision language BEIT)的工作,也是类似的思路,只不过是用一个Transformer编码器来做多模态的任务。
局限性:
如果想让VA-VAE做生成,就需要单独训练一个prior网络,在论文里,作者就是训练了一个pixcl-CNN(利用训练好的codebook去做生成)。
VQ-VAE 2
本身是对VQ-VAE的简单改进,是一个层级式的结构。VQ-VAE2不仅做局部的建模,而且还做全局的建模(加入attention),所以模型的表达能力更强了。同时根据codebook学了一个prior,所以生成的效果非常好。总体来说VQ-VAE2是一个两阶段的过程:
训练编解码器,使其能够很好的复现图像
训练PixelCNN自回归模型,使其能够拟合编码表分布,从而通过随机采样,生成图片
stage1:训练一个分层的VQ-VAE用于图像编码到离散隐空间
输入图像 x,通过编码器生成向量$E ( x )$ ,然后采用最近邻重构,将$E ( x )$ 替换为codebook的中的一个nearest prototype vector。codebook可以理解为离散的编码表,举一张人脸图像为例codebook就包括头发颜色,脸型,表情和肤色等等。因此,量化就是通过编码表,把自编码器生成的向量$E ( x ) $离散化:
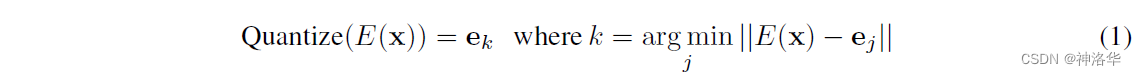
stage2:在离散隐空间上拟合一个PixelCNN先验
- 经过Stage1,将图片编码为了整数矩阵,所以在Stage2用自回归模型PixelCNN,来对编码矩阵进行拟合(即建模先验分布)
- 通过PixelCNN得到编码分布后,就可以随机生成一个新的编码矩阵,然后通过编码表E EE映射为浮点数矩阵,最后经过deocder重构得到一张图片
原文中还有再加middle level,实验结果表明加了middle level之后,生成的图像清晰度更高)
扩散模型
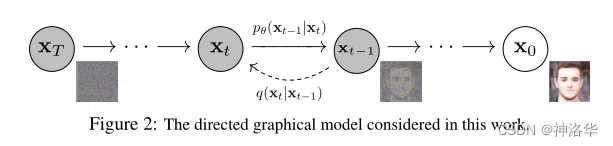
扩散模型包含两个过程:前向扩散过程(forword)和反向生成过程(reverse):
- 前向扩散过程:对数据逐渐增加高斯噪音直至数据变成随机噪音的过程(噪音化)
- 反向生成过程:从随机噪音开始逐步去噪音直至生成一张图像(去噪)
BackBone(大部分扩散模型选用U-Net)
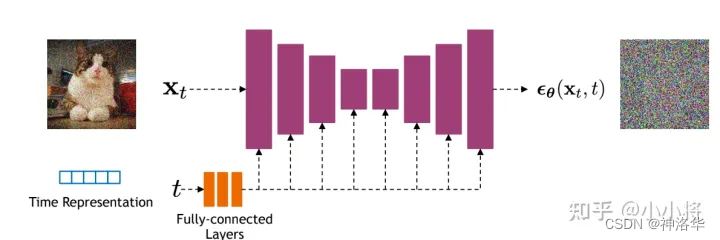
U-Net里还有一些skip connection的操作,可以直接将前面的信息传递给后面,以恢复更多的细节。后续还有一些改进,比如在U-Net里加一些attention操作,可以使图像生成的更好,共享参数。
局限性:训练推理慢
DDPM
贡献 :
从预测转换图像改进为预测噪声,每次直接从$x_{t}$预测$x_{t-1}$,这种图像到图像的转化不太好优化。所以作者考虑直接去预测从$x_{t}$
到$x_{t-1}$ 这一步所添加的噪声$\varepsilon$,这样就简化了问题。time embedding:U-Net模型输入,除了当前时刻的$x_{t}$ ,还有一个输入time embedding(类似transformer里的正弦位置编码),主要用于告诉 U-Net模型,现在到了反向过程的第几步。
目标函数:DDPM采用了一个U-Net 结构的Autoencoder来对t时刻的高斯噪声z进行预测。训练目标即希望预测的噪声和真实的噪声一致,所以目标函数为预测噪声和z 的L1 Loss:
$p(\mathbf{x}{t-1} \vert \mathbf{x}t)=\left | f{\theta}(x{t},t) \right|$, t为时间
只预测正态分布的均值
正态分布由均值和方差决定。作者在这里发现,其实模型不需要学方差,只需要学习均值就行。
Improved DDPM
improved DDPM作者就觉得如果方差效果应该会更好,改了之后果然取样和生成效果都好了很多。
DDPM添加噪声时采用的线性的variance schedule改为余弦schedule,效果更好(类似学习率从线性改为余弦)
ADM Nets
使用大模型:加大加宽网络、使用更多的自注意力头attention head,加大自注意力scale(single-scale attention改为multi-scale attention)
提出了新的归一化方式——
Adaptive Group Normalization,在文章就是根据步数进行自适应的归一化。这个方法是对group归一化的一个改进: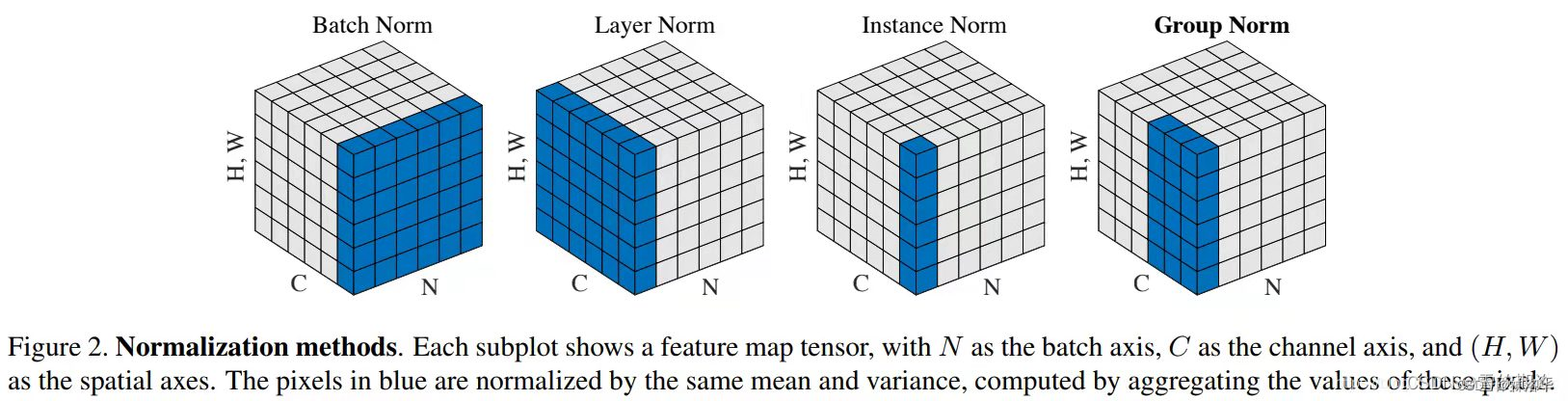
$AdaGN(h,y=[y_s,y_b])=y_s*GroupNorm(h)+y_b$
上面公式中的$h$是残差块激活函数的输出,$y$是一个线性层对时步和后面用到的类别信息的嵌入。组归一化是对输入的通道方向进行分组归一化的归一化方法.
使用
classifier guidance的方法,引导模型进行采样和生成。这样不仅使生成的图片更逼真,而且加速了反向采样过程。论文中,只需要25次采样,就可以从噪声生成图片。- 训练一个简单是图片分类器
- CLIP guidance:将简单的分类器换成CLIP之后,文本和图像就联系起来了
- image侧引导:除了利用图像重建进行像素级别的引导,还可以做图像特征和风格层面的引导,只需要一个gram matrix就行。
- text侧:可以用训练好的NLP大模型做引导
更新后的损失 : $p(x_{t−1}∣x_t)=∥z−f_θ*(x_t,t,y)∥$
Classifier free guidance
classifier free guidance的方式,只是改变了模型输入的内容,除了 conditional输入外(随机高斯噪声输入加引导信息)还有 unconditional 的 采样输入。两种输入都会被送到同一个 diffusion model 从而让其能够具有无条件和有条件生成的能力。得到有条件输出$f_{\theta }(x_{t},t,y)$和无条件输出$f_{\theta }(x_{t},t,\phi )$f后,就可以用前者监督后者,来引导扩散模型进行训练了。最后反向扩散做生成时,我们用无条件的生成,然后加上之前训练的偏移,也能达到类似有条件生成的效果。这样一来就摆脱了分类器的限制
DALL·E2
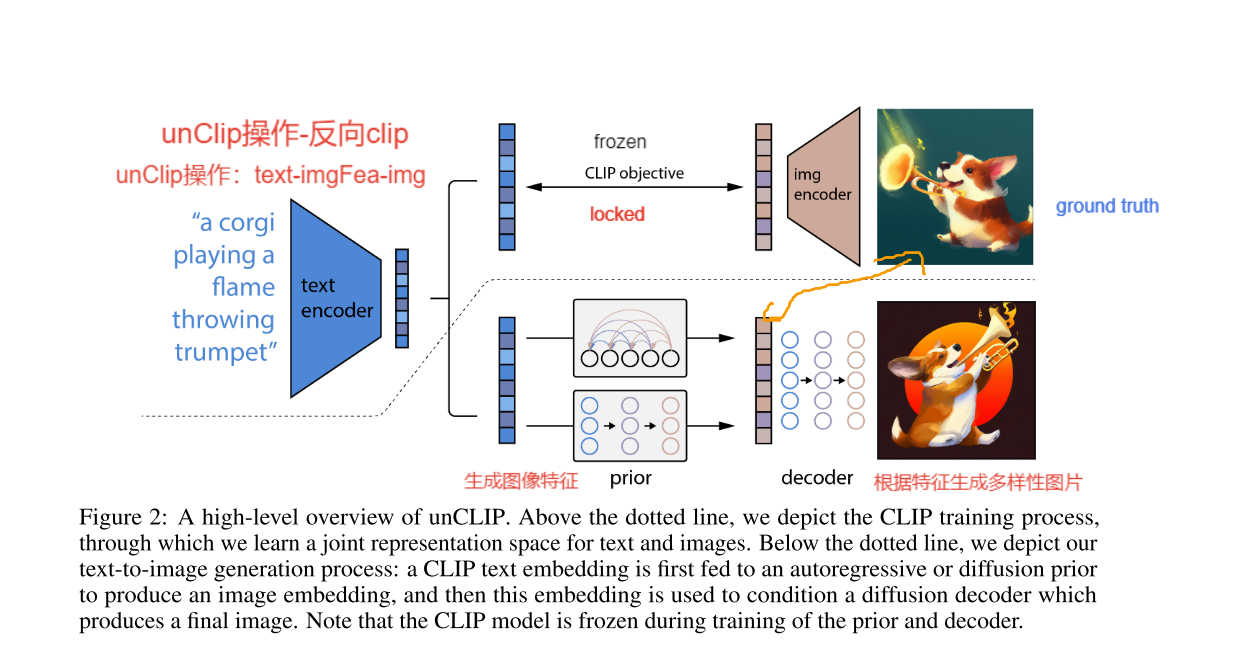
prior:先验模型$P(z_i|y)$ ,根据标题$y$生成CLIP的图像特征$z_i$。
decoder :解码器$P(x|z_i,y)$,生成以CLIP图像特征$z_i$ (和可选的文本标题 $y$)为条件的图像$x$
跟上面讲的一样,prior模型的输入就是CLIP编码的文本特征,其ground truth就是CLIP编码的图片特征,因为是图文对输入模型,CLIP是都能编码的。
decoder
decoder就是使用扩散模型,生成以CLIP图形特征(和可选标题$y$)为条件的图像,这部分就是在GLIDE基础上改进的。利用了CLIP guidance和classifier-free guidance
其次,为了提高分辨率,DALL·E2还用了层级式的生成,也就是训练了两个上采样扩散模型。一个将图像的分辨率从64×64上采样到256×256,另一个接着上采样的1024×1024。同时,为了提高上采样器的鲁棒性,还添加了噪声(第一个上采样阶段使用高斯模糊,对于第二个阶段,使用更多样化的BSR退化)。
prior
prior用于从文本特征生成图像特征,这部分作者试验了两种模型,两种模型都用了classifier-free guidance,因 为效果好。
- AR(自回归模型)
- 扩散模型:使用的是
Transformer decoder处理序列。因为这里输入输出都是embedding序列,所以使用U-Net不太合适。
总结:大力出奇迹
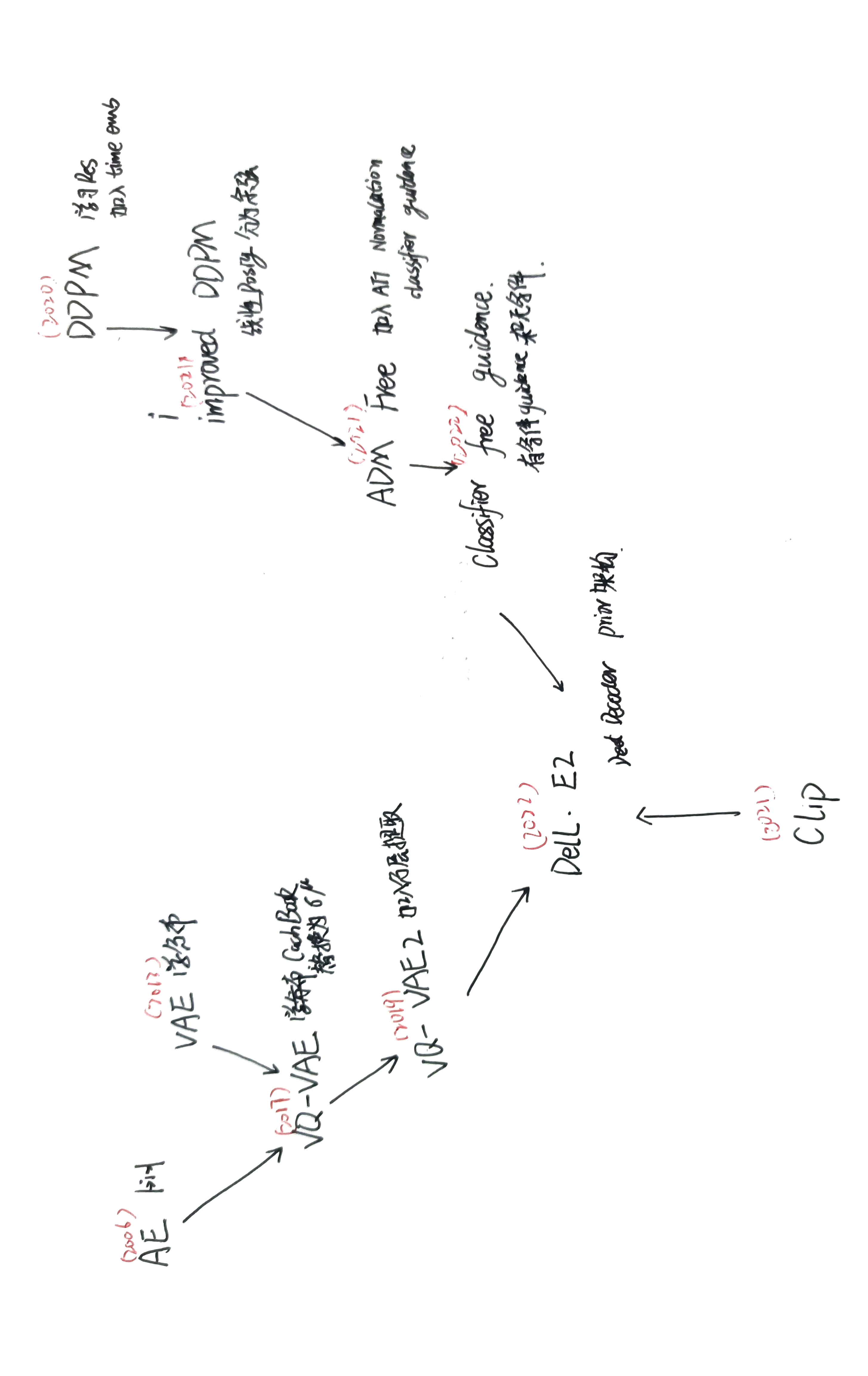
图像生成这一块的技巧很多,经常连一个模型总览图都很难画出来。但是讲完这么多之后,会发现这些技巧有的时候有用,有的时候没用。
- DDPM提出将直接预测图像改为预测噪声,可以简化优化过程。但是DALL·E2这里又没有沿袭这种预测噪声的做法。
- DALL·E2提出如果有显式的生成图片特征的过程,模型效果会好很多,所以采用了两阶段生成方式。但是Imagen直接上一个U-Net就解决了,更简单,效果也很好。
- CLIP和DALL·E2都说自回归模型训练太贵了,训练太不高效了。但是在7月左右,谷歌又推出了Parti,用pathways模型做自回归的文本图像生成,效果直接超越了DALL·E2和Imagen。