论文精读-视频理解综述-2021
0. 综述
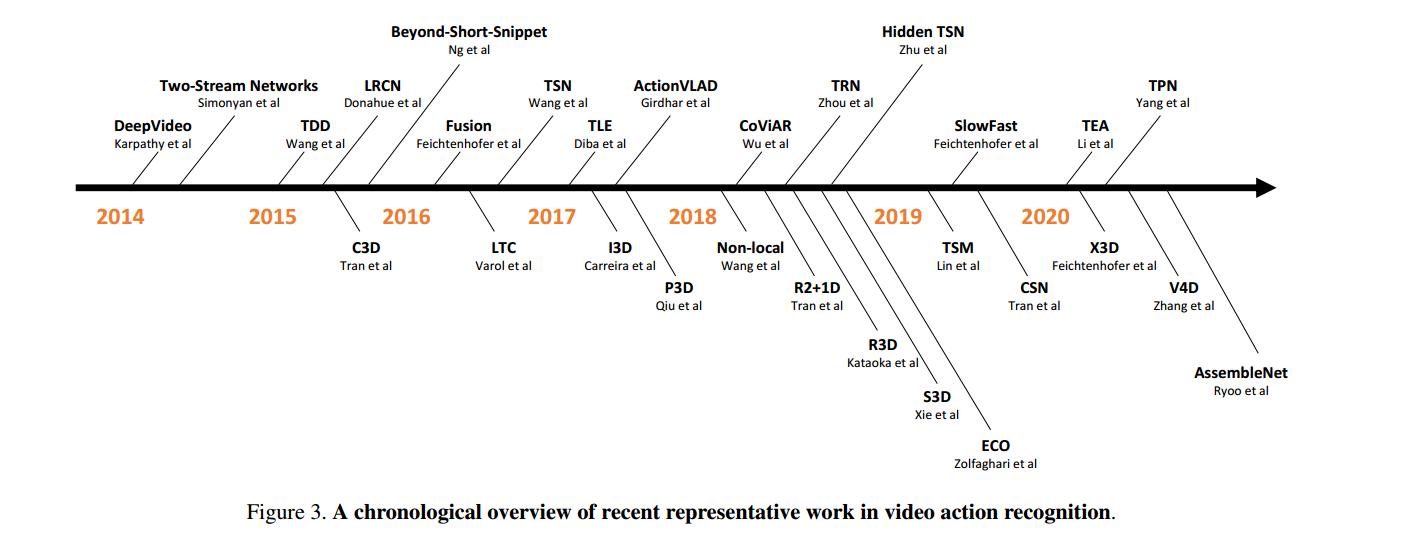
1. Hand-Crafted- >CNN
1.1 DeepVideo
** **探索可以用在视频上使用的各种神经网络:各种方法都差不多,第四种方法好些
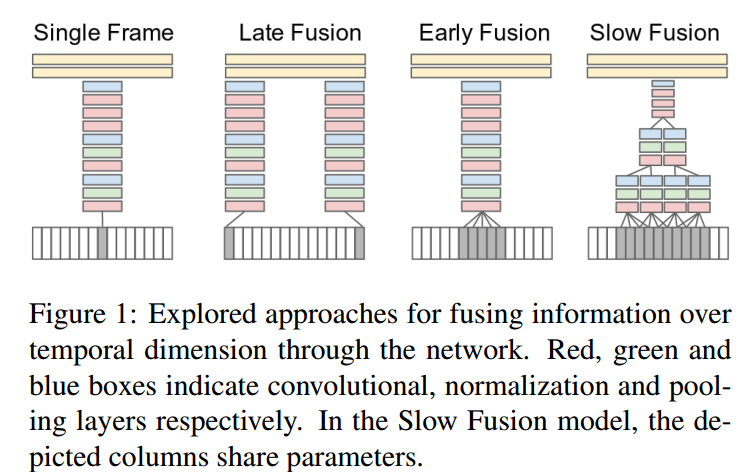
开始讲故事
多分辨率神经网络:两个权值共享的网络,一个处理低分辨率的图像,一个处理高分辨率的图像(图片的中心区域),人为提高了注意力
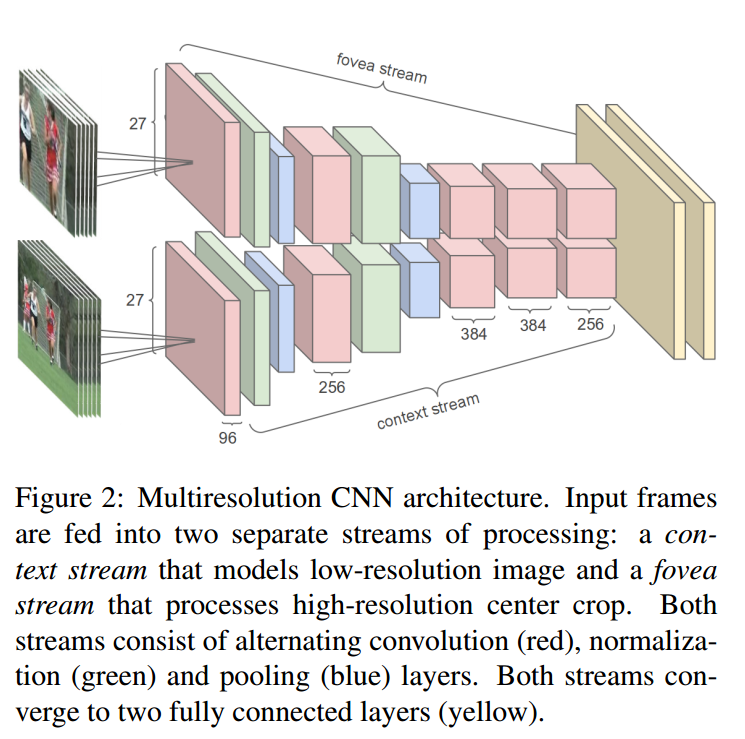
2. Two-Stream
双流网络在这里指的是同时使用光流抽取的特征和图片(视频帧)本身的特征进行网络训练;经测试这种方法可以很大地提高网络捕捉动态效果的能力
2.1 Two-Stream Networks

late fusion->early fusion; AlexNet->Resnet Vgg; 加入
2.2 Beyond Short Snippets
想办法适应更长时间的视频、动作特征的提取等等。Pooling ,Lstm提取时序信息,但是LSTM效果不明显,可能是一个短的时序信息变化不大,内容相似,Lstm学习不到有用的信息,需要长视频/变化大
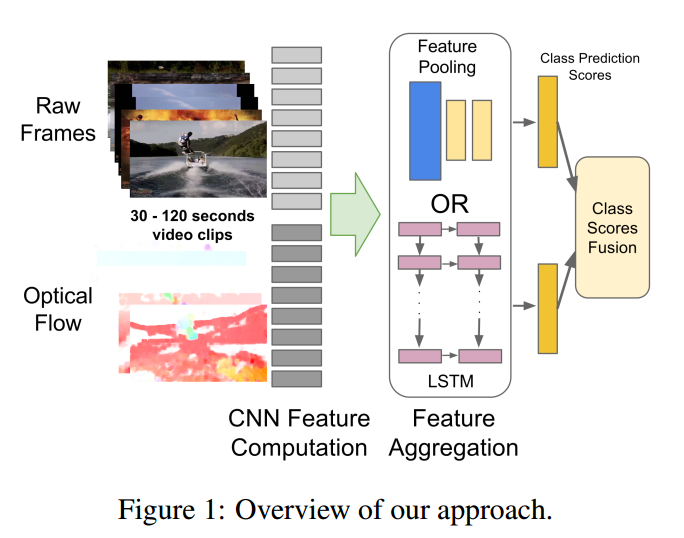
2.3 Convolutional Fusion
当有时间流和空间流两个网路之后,如何保证时间和空间的特征图在同样的位置上他们产生的通道respones是差不多能联系起来的。
通常对于一个具有三个维度特征的数据而言我们有很多的探究方向:
- Spatial fusion : 空间特征融合
- Time fusion : 时间维度特征融合
- 在网络的一层进行特征融合
时间维度上的融合
蓝:空间 绿:时间
2.4 TSN
步骤
- 将视频分为多个段,从每段中抽取一帧的RGB图片,然后对这个图片进行光流计算
- 重复工作,对不同段进行相同工作
- 如果段分得比较小,那么抽取的特征在理论上是描述的同一个物体的运动特征
- 最后进行一个特征融合,进行分类工作
技巧:
- 视频分段
- ImageNet训练的模型应用到光流
- partial BN
- 数据增强 专门对边角裁剪 改变长宽比 {256 224 192 168}
3. 3D ConvNet
3.1 C3D
C3D主要是提供了一种抽取特征做其他任务的方法(因为训练一个大型的3D网络非常昂贵,很多研究者无法训练),C3D作者将训练好的模型的接口提供给其他人,其他人只需要输入视频就可以得到抽取的特征(4096序列),这样就可以根据抽取的特征进行后续处理了。
3.2 I3D-Inflated
贡献:
- 可以方便地将2D网络扩张到3D之中-直接复制权重,可以用巧妙的方法利用预训练模型
- 提出了kinetics数据集
Two-Stream 3D-ConvNet效果最好
在空间、时间和网络深度上对感受野的增长进行调整:对于图片的两个空间维度,我们通常使用相同的卷积长度/池化长度,但是在时间维度上并不相同,时间维度的kernel长度取决于帧率和图片大小。如果在时域内变化太块,它可能会混淆不同物体的边缘,破坏早期的特征检测,而如果它增长得太慢,它可能无法很好地捕捉场景的动态。动态性。
3.3 Non-local
加入自注意力,即插即用
3.4 R2+1D
3.5 SlowFast
讲故事:慢的分支网络学习视频中的静态特征,快分支学习视频中的动态特征。
- 慢分支使用小输入,大网络
- 快分支使用大输入,小网络
- 中间使用natural connection进行特征融合
4. Video Transformer
4.1 Space-Time Attention
- 直接将Attention应用到图片的方法迁移到视频之中(空间注意力)
- 在时间上和空间上分别做三个自注意力机制,进行融合
- 拆分为空间和时间上分别进行注意力机制计算(时间-> 空间)文章提出
- local global拆分(在局部进行注意力计算)
- 沿着特定的轴进行注意力计算(将三维拆分为三个一维进行注意力机制计算)
想法简单、效果好、容易迁移、可以用于处理超过1min的视频
5. 总结
对于时间和空间相结合的一些策略可以借鉴
- 3D卷积怎么做:最新的方法都是做一些拆分,将3D卷积分为时间和空间分别的卷积
- 特征融合的方法:early fusion、latent fusion
- 三维网络中一些关键层(如BN)如何设置:只要第一层的BN?
- 3D网络中的时间维度尽量不要做下采样
- Vision Transformer降维打击,提高精度、减小计算消耗、加大处理时长(看到更长的时序信息)